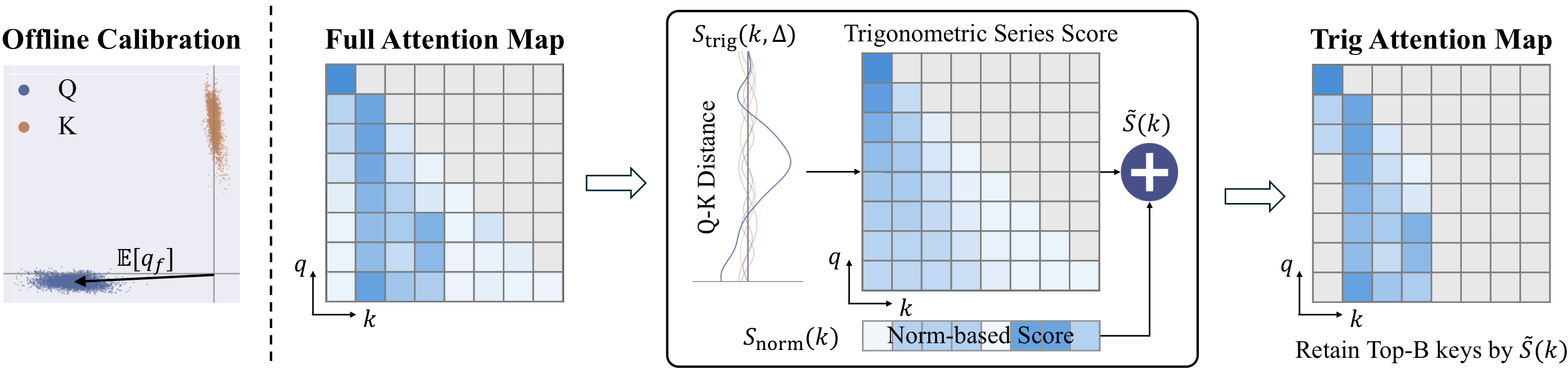
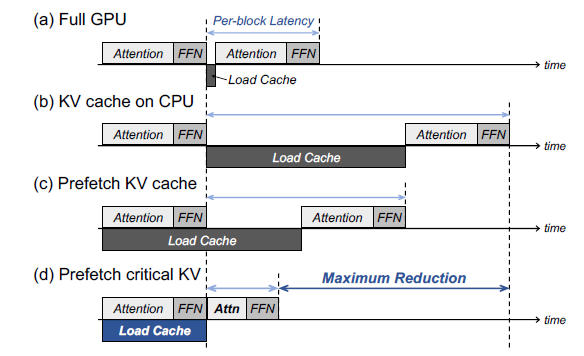
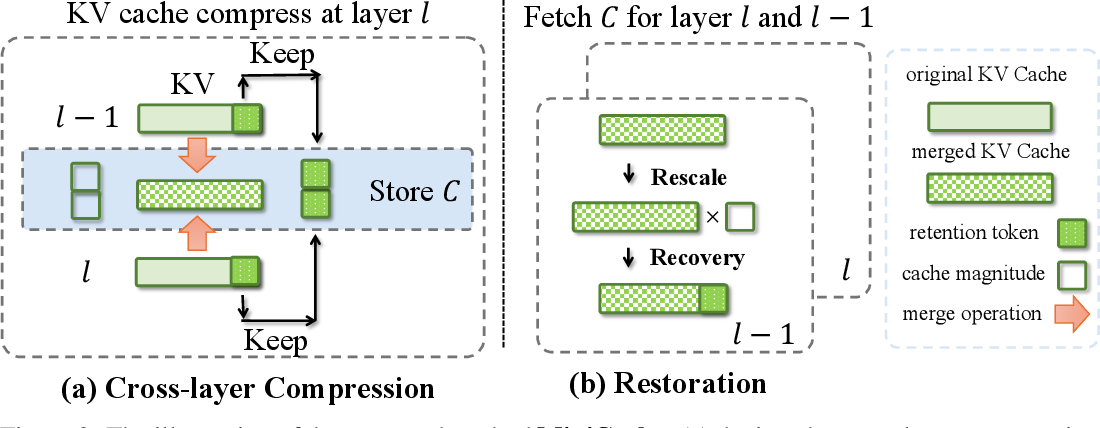
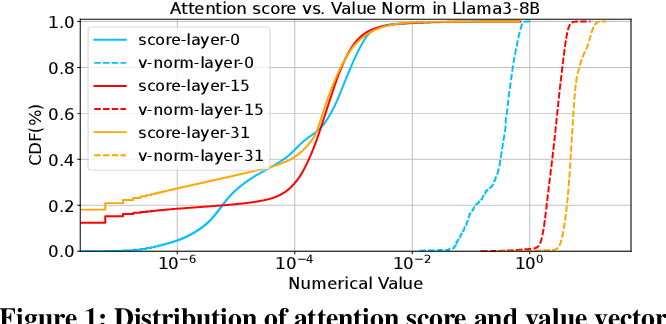
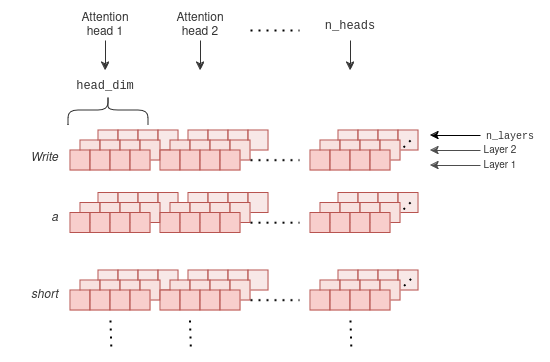
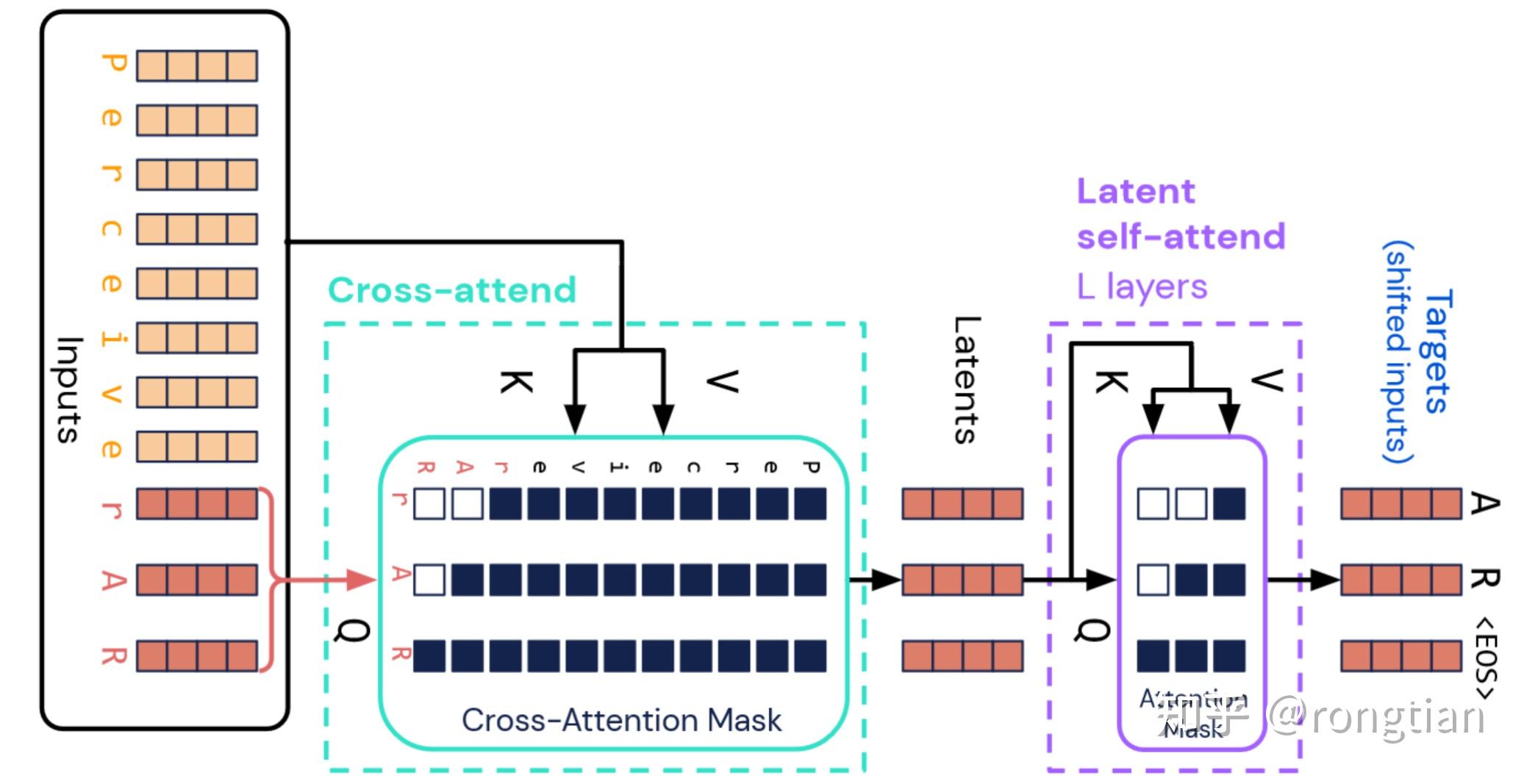
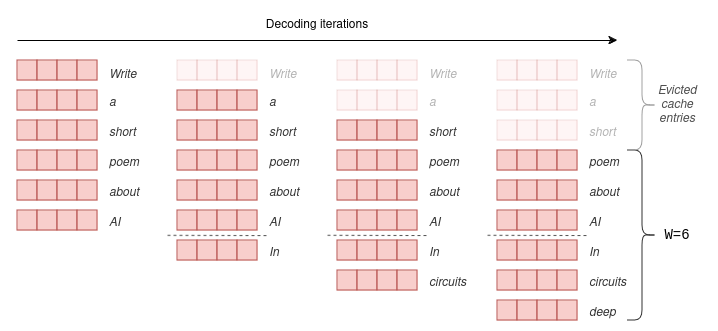
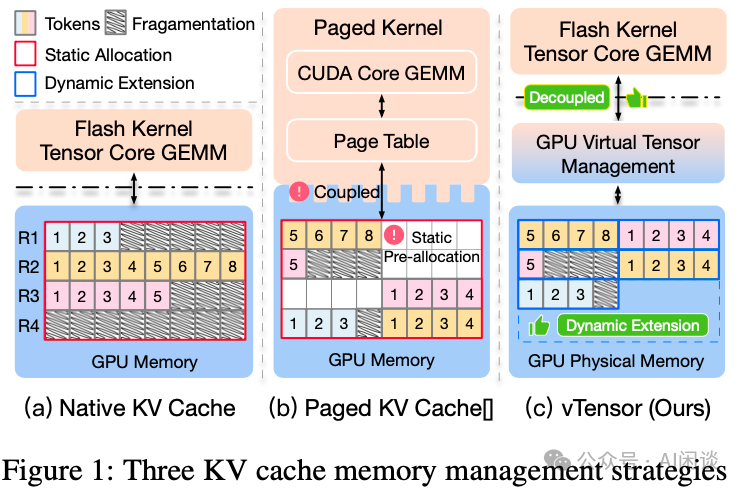
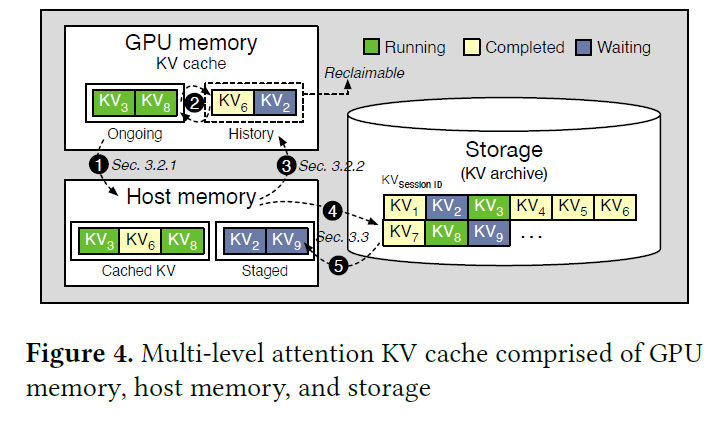
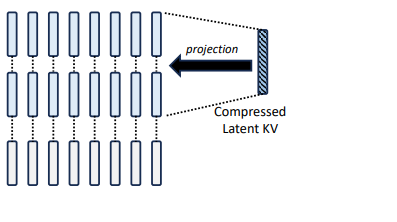
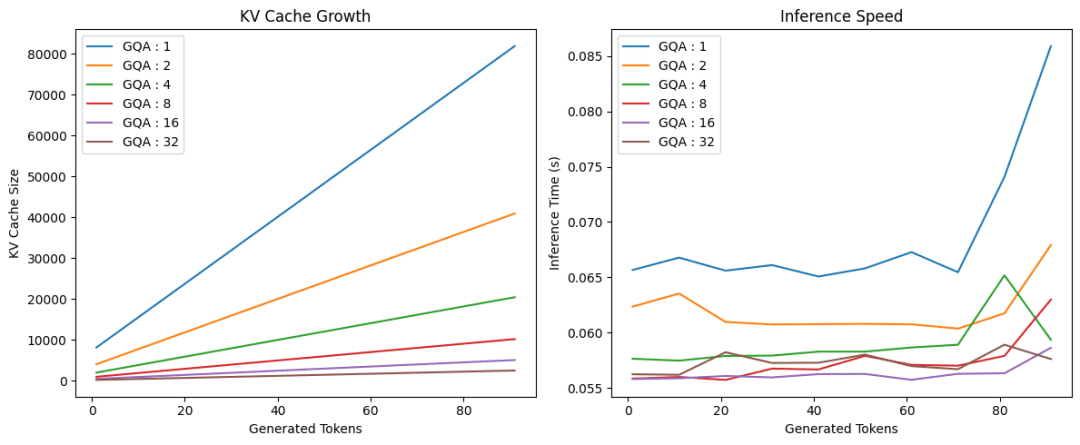
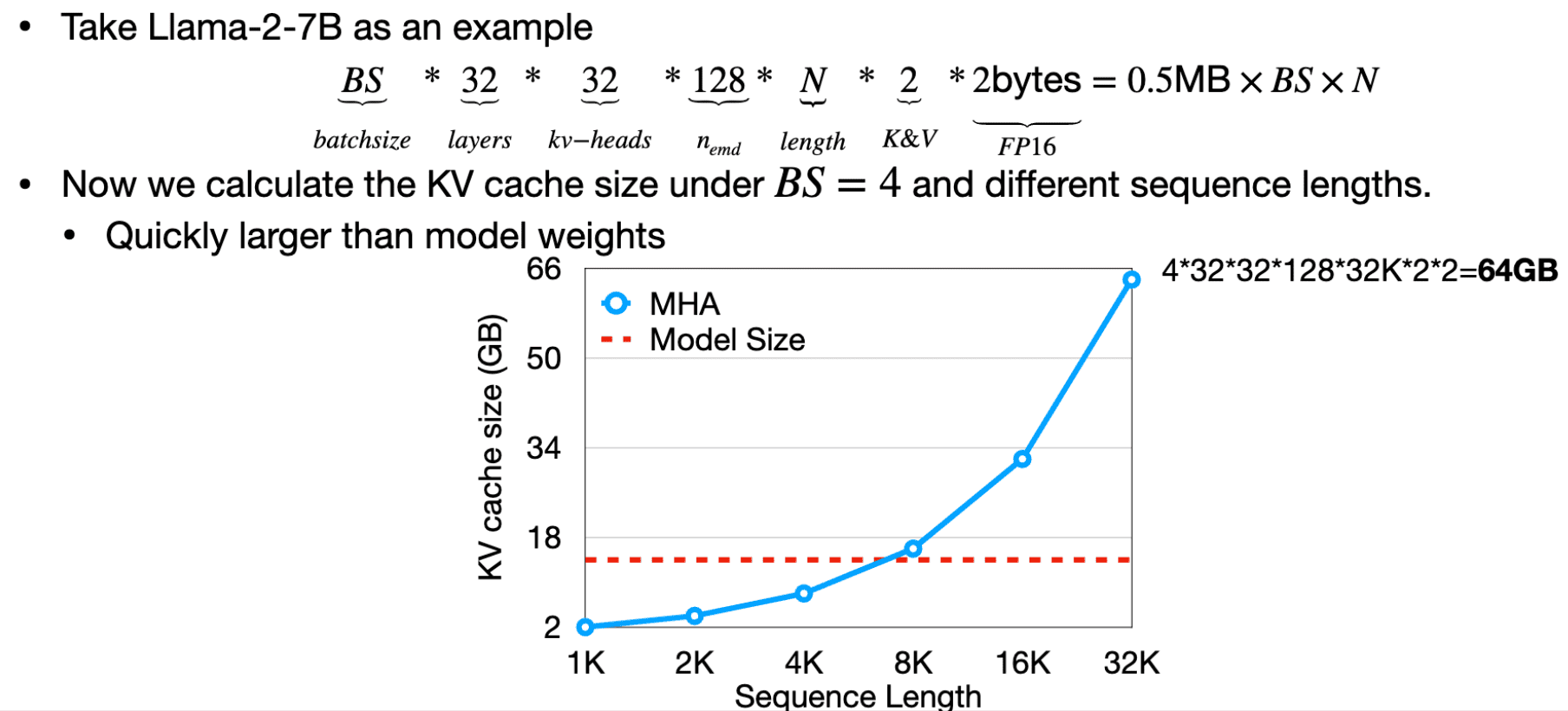
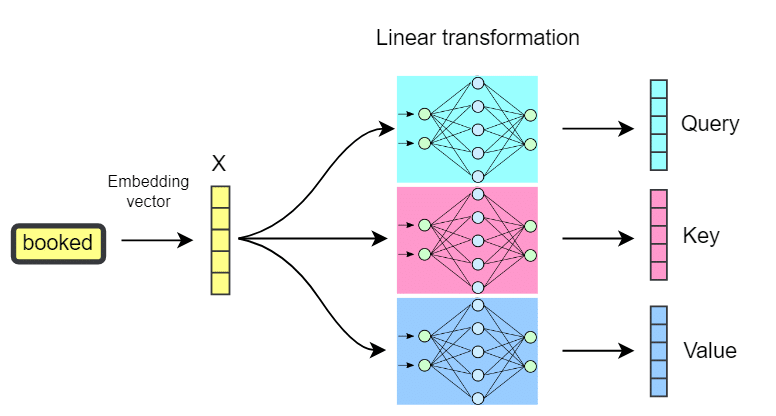
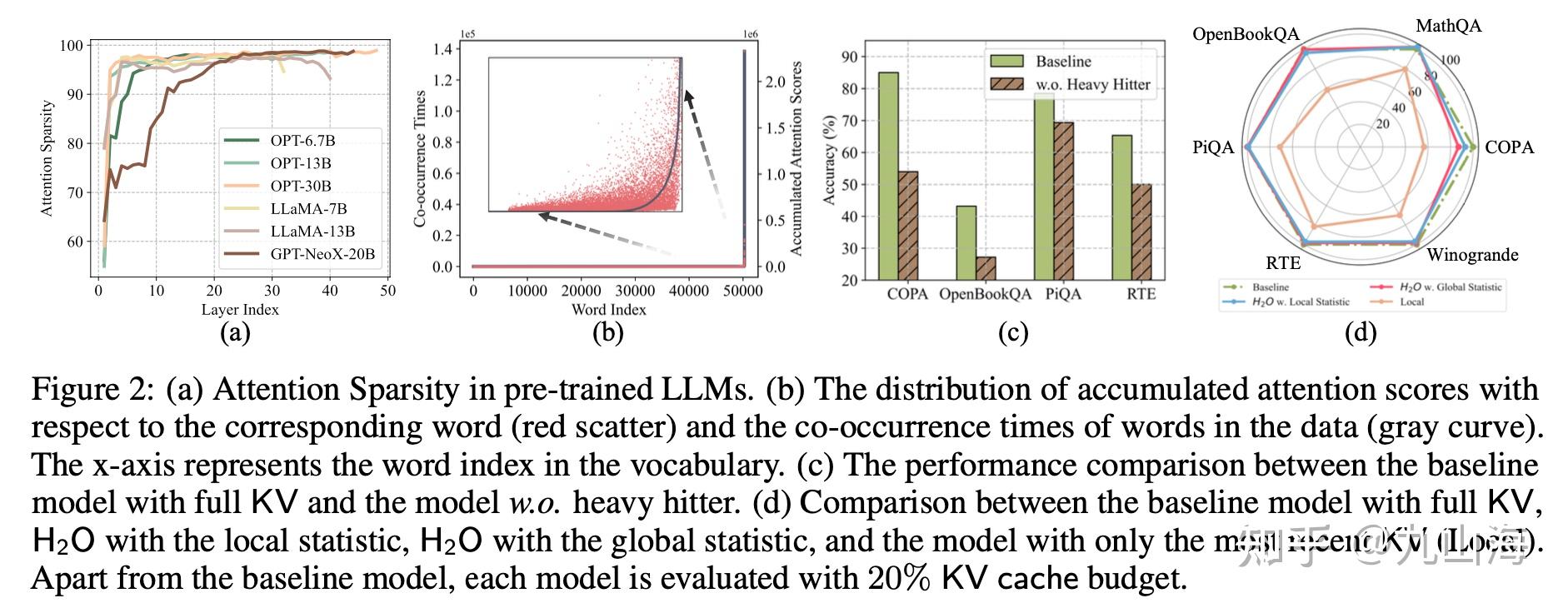
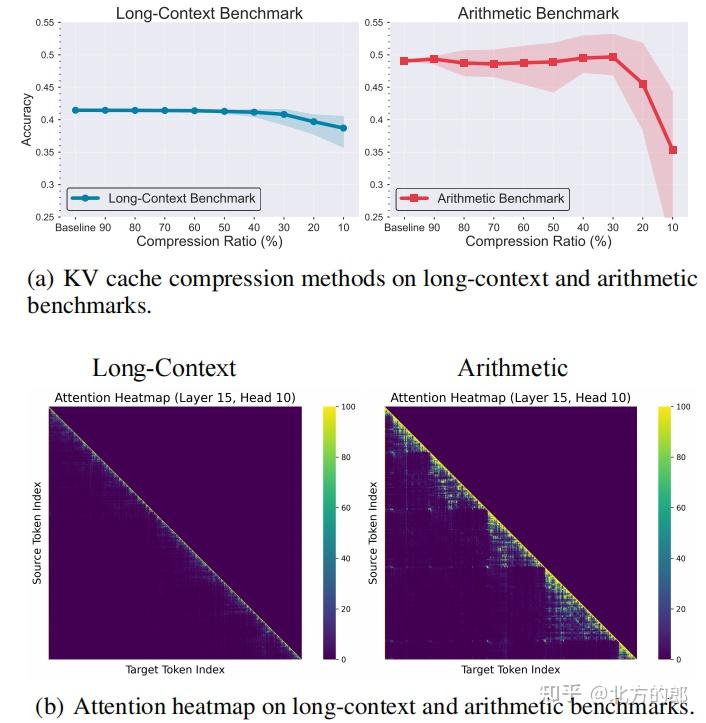
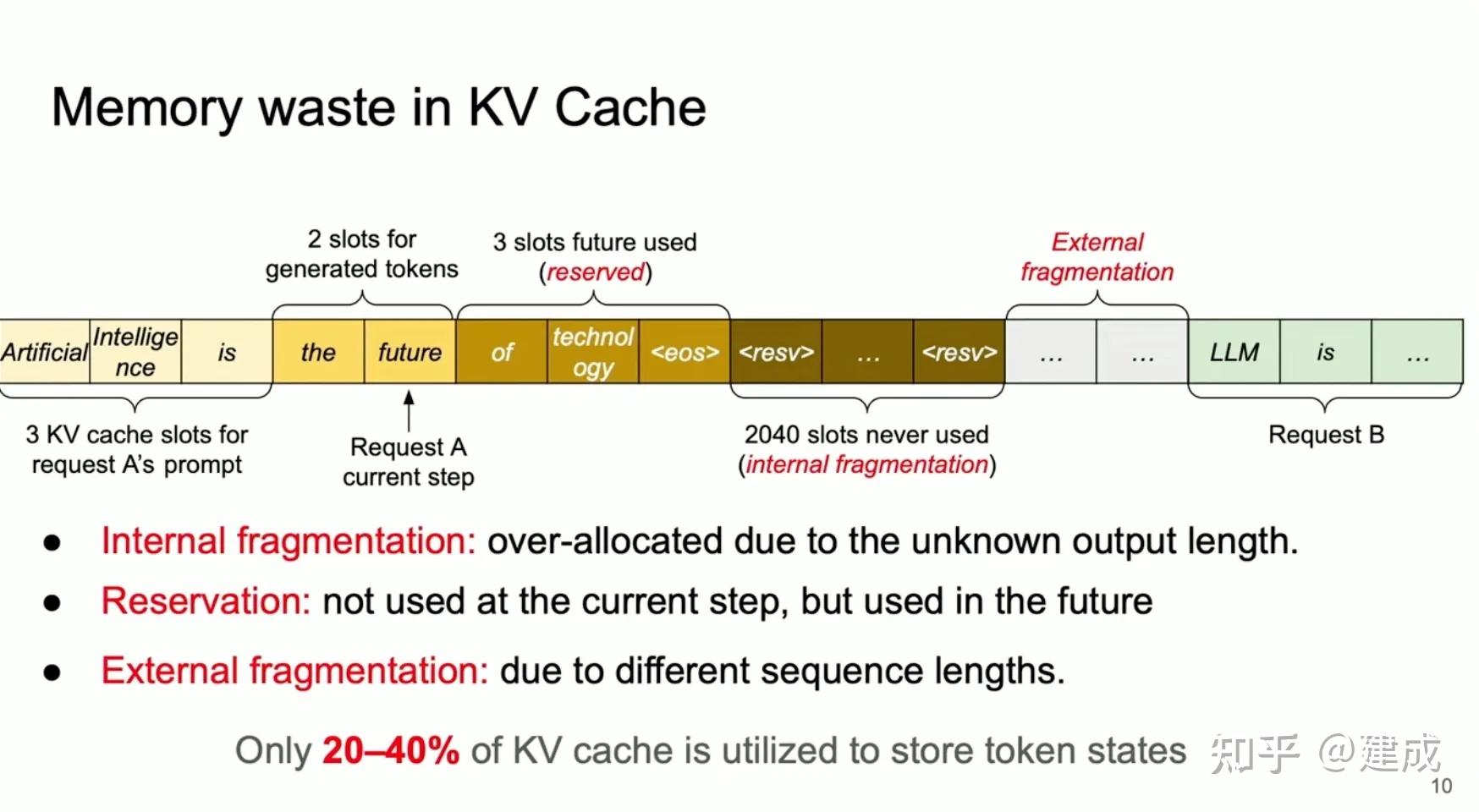
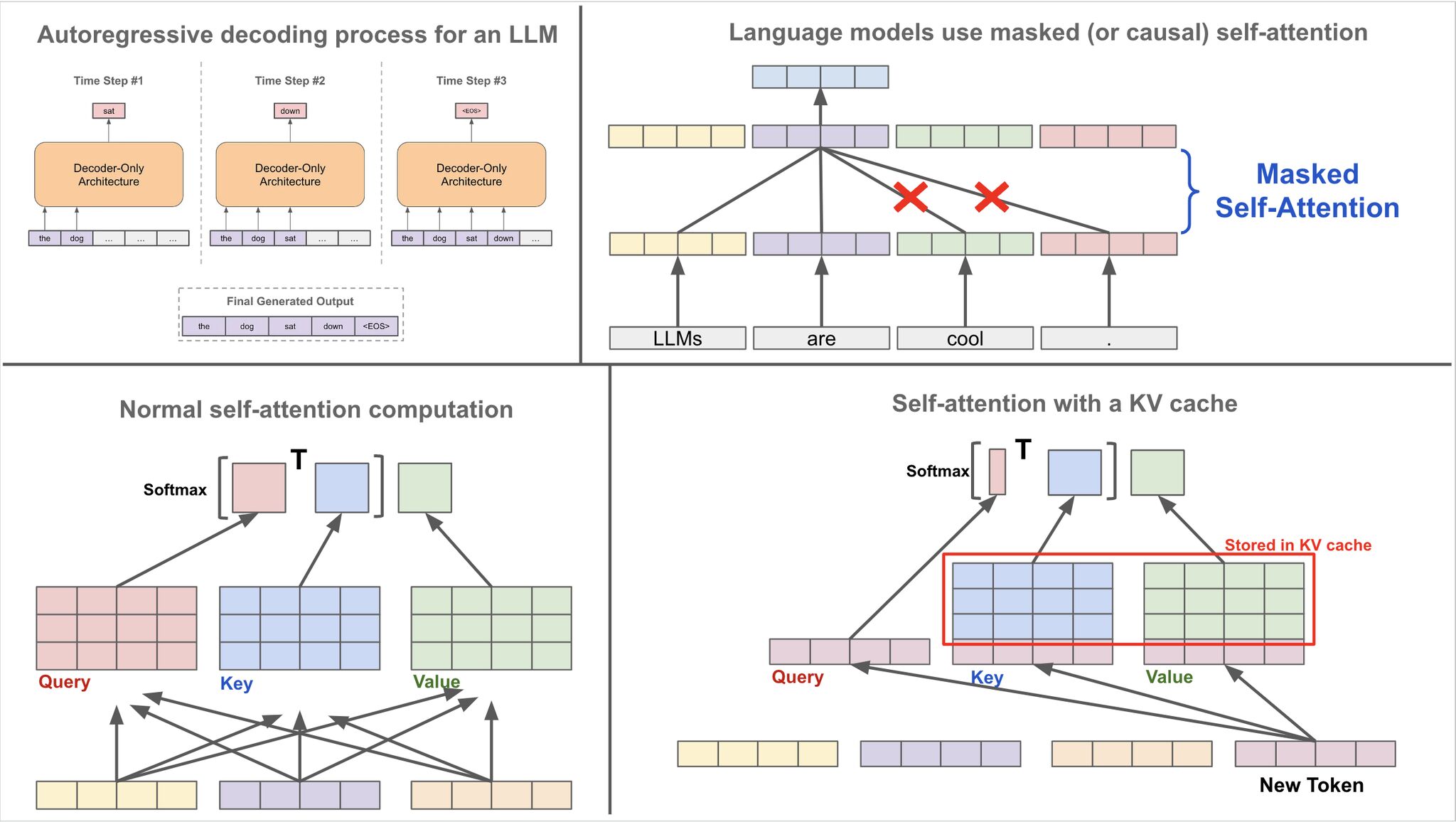
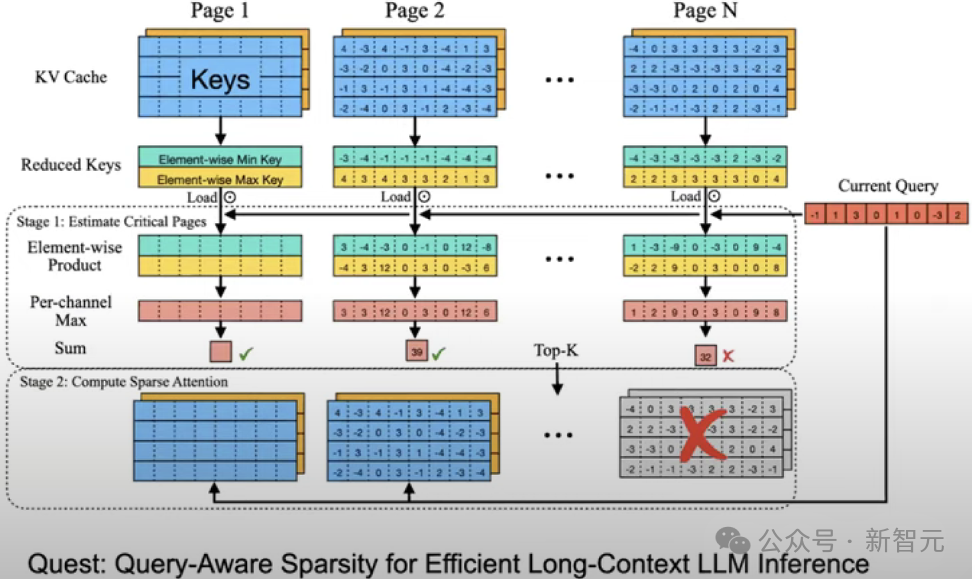
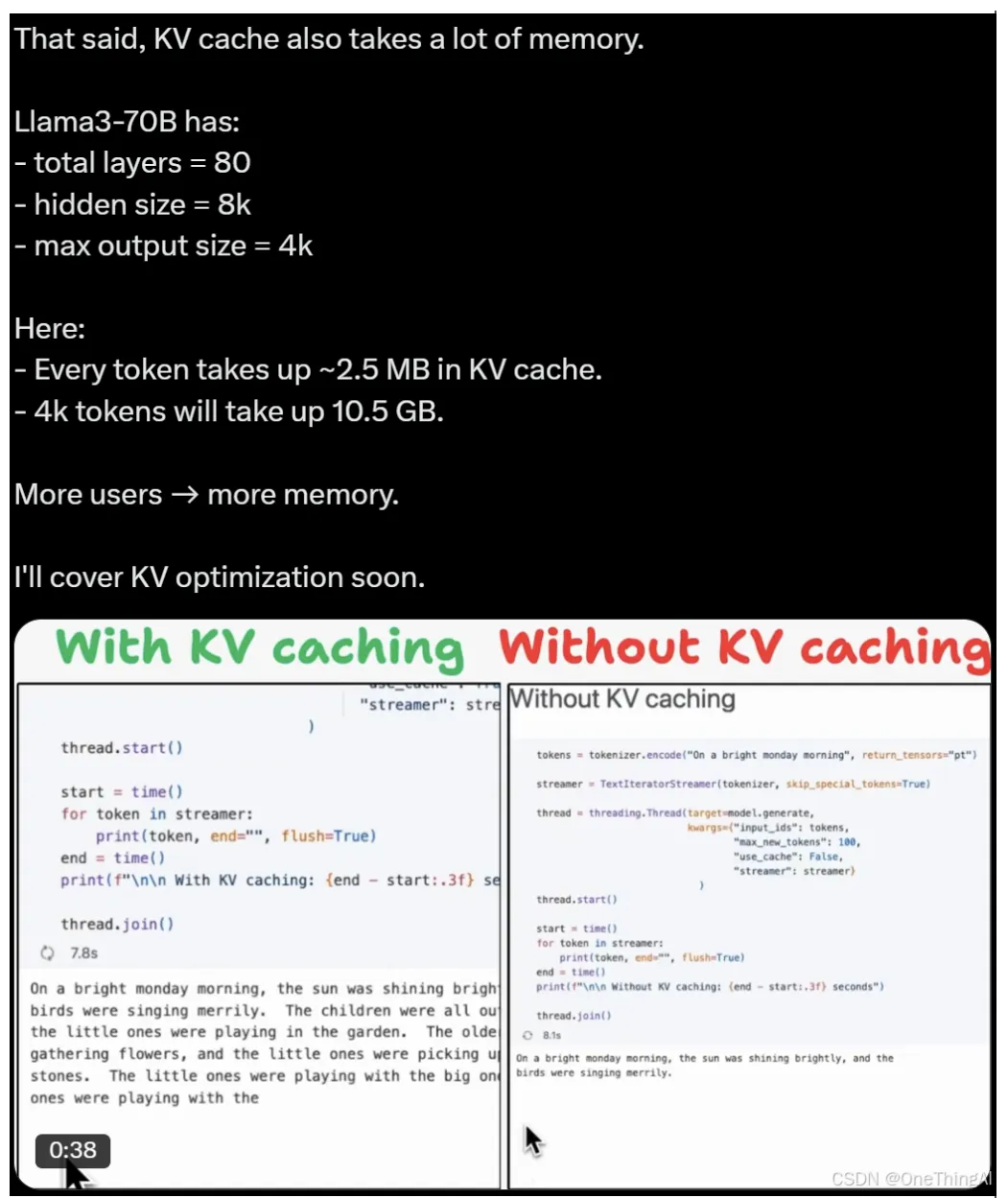
R-KV: Redundancy-aware KV Cache Compression for Reasoning Models | alphaXiv
Paper page - R-KV: Redundancy-aware KV Cache Compression for Reasoning ...
FastKV: KV Cache Compression for Fast Long-Context Processing with ...
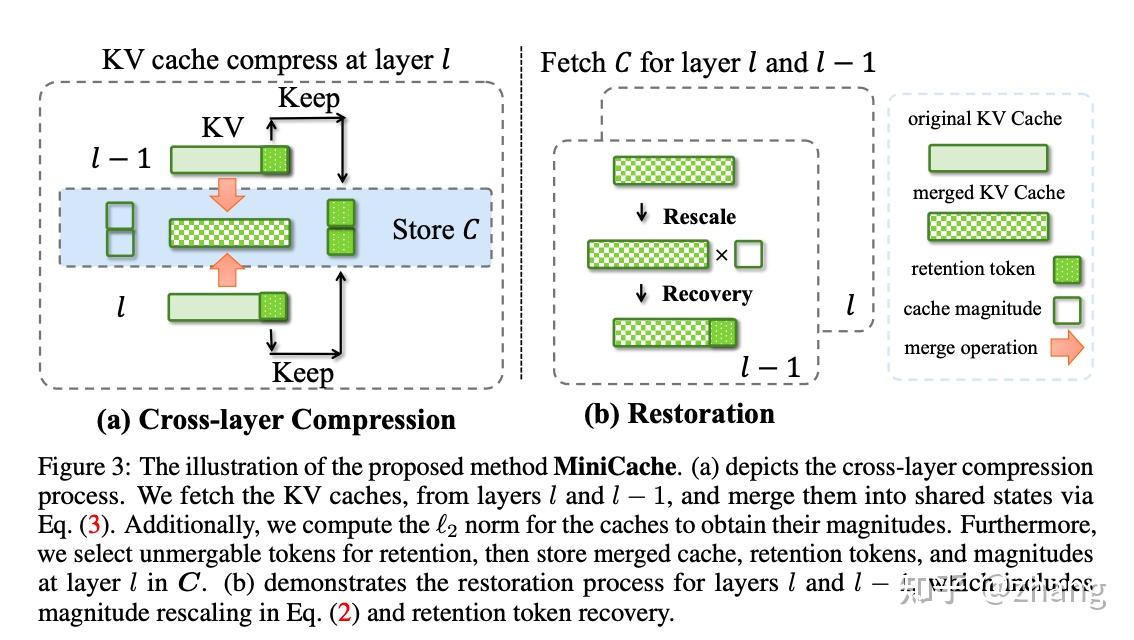
[论文评述] MiniCache: KV Cache Compression in Depth Dimension for Large ...
[논문 리뷰] Compressing KV Cache for Long-Context LLM Inference with Inter ...
KV Cache compression with Inter-Layer Attention Similarity for ...
Figure 3 from MiniCache: KV Cache Compression in Depth Dimension for ...
Paper page - Layer-Condensed KV Cache for Efficient Inference of Large ...
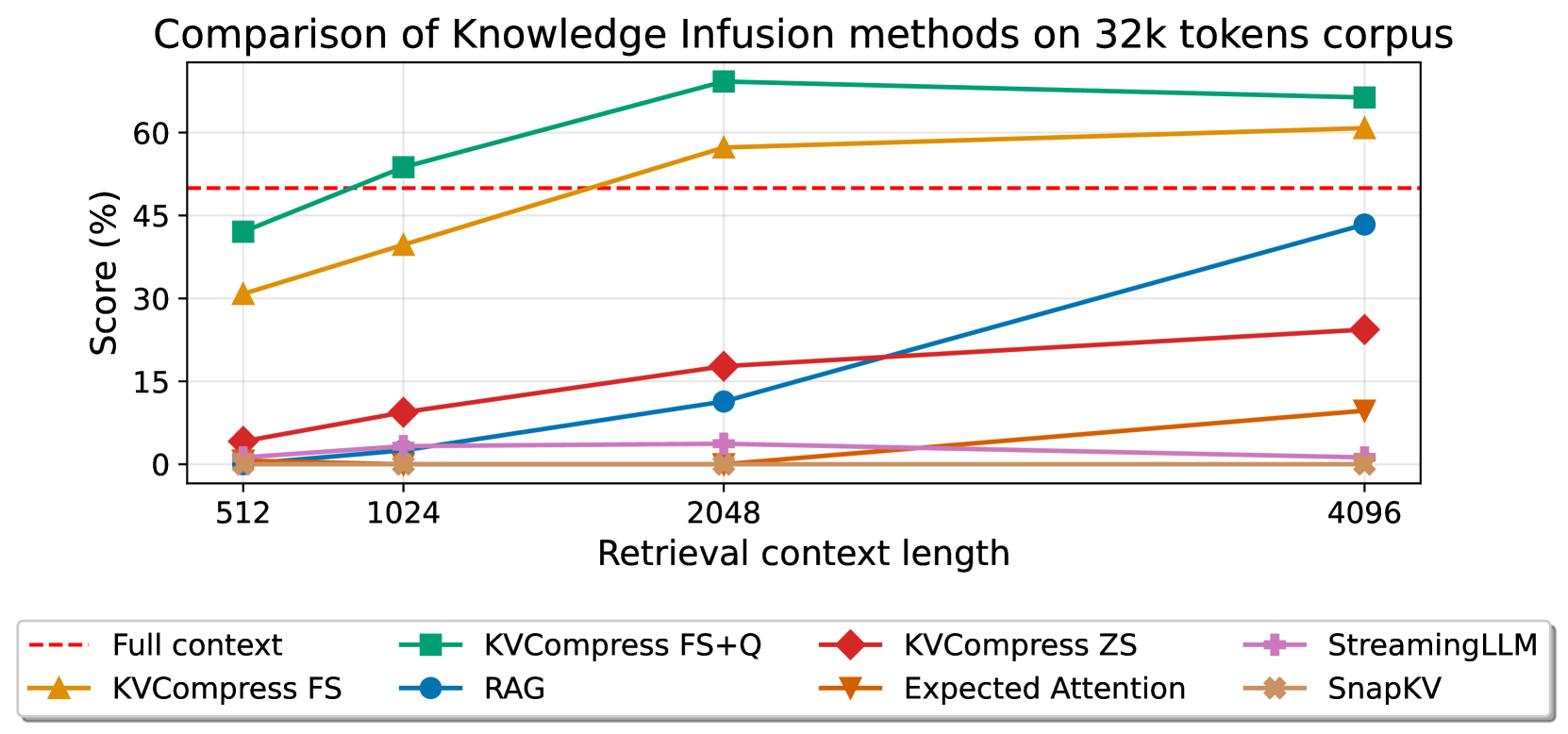
Beyond RAG: Task-Aware KV Cache Compression for Comprehensive Knowledge ...
Layer-Condensed KV Cache for Efficient Inference of Large Language ...
Figure 1 from Unifying KV Cache Compression for Large Language Models ...
Figure 4 from RazorAttention: Efficient KV Cache Compression Through ...
Table 1 from KV Cache Compression for Inference Efficiency in LLMs: A ...
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression ...
Figure 1 from Lossless KV Cache Compression to 2% | Semantic Scholar
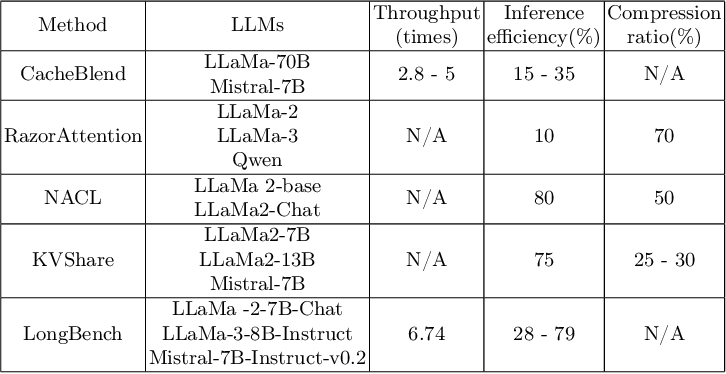
RazorAttention: Efficient KV Cache Compression Through Retrieval Heads ...
SCOPE: KV Cache optimization framework for long-context generation in ...
Figure 7 from Layer-Condensed KV Cache for Efficient Inference of Large ...
Figure 13 from Layer-Condensed KV Cache for Efficient Inference of ...
Unifying KV Cache Compression for LargeLanguage Models with LeanKV——使用 ...
Figure 2 from Layer-Condensed KV Cache for Efficient Inference of Large ...
Figure 1 from RazorAttention: Efficient KV Cache Compression Through ...
Figure 1 from Layer-Condensed KV Cache for Efficient Inference of Large ...
(PDF) MiniCache: KV Cache Compression in Depth Dimension for Large ...
Figure 6 from Layer-Condensed KV Cache for Efficient Inference of Large ...
Figure 4 from Layer-Condensed KV Cache for Efficient Inference of Large ...
Figure 12 from Layer-Condensed KV Cache for Efficient Inference of ...
Memory Optimization in LLMs: Leveraging KV Cache Quantization for ...
Techniques for KV Cache Optimization in Large Language Models
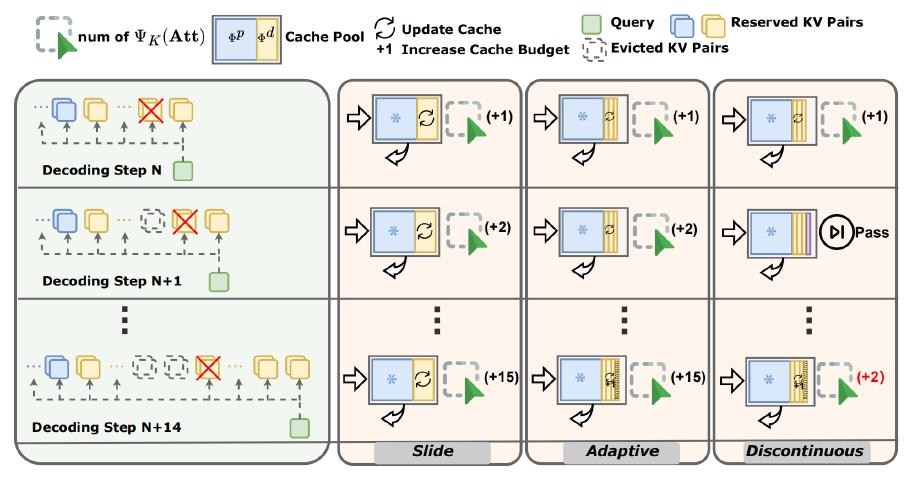
[论文评述] KeepKV: Eliminating Output Perturbation in KV Cache Compression ...
NeurIPS Poster KV Cache is 1 Bit Per Channel: Efficient Large Language ...
KV Cache 中的 Context Compression - 知乎
MiniKV: Pushing the Limits of 2-Bit KV Cache via Compression and System ...
Multi-Query Attention Explained | Dealing with KV Cache Memory Issues ...
SCBench: A KV Cache-Centric Analysis of Long-Context Methods · HF Daily ...
SCBench: A KV Cache-Centric Analysis of Long-Context Methods · AI Paper ...
Welcome to my blog! - Understanding KV Cache
LLM Inference: Accelerating Long Context Generation with KV Cache ...
【文献阅读】Key, Value, Compress: A Systematic Exploration of KV Cache ...
LLM 推理的 Attention 计算和 KV Cache 优化:PagedAttention、vAttention 等_paged ...
Understanding KV Cache and Paged Attention in LLMs: A Deep Dive into ...
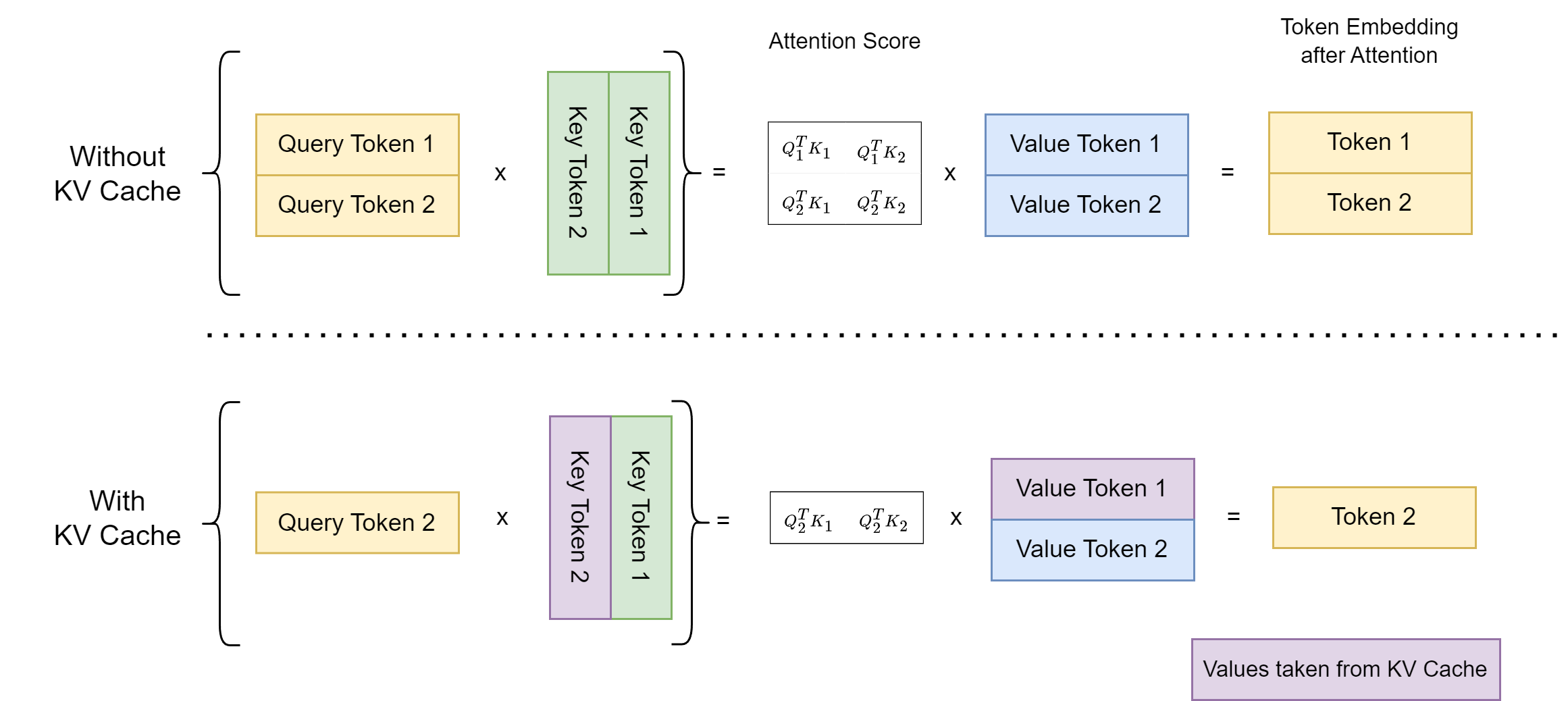
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
[论文评述] LLMs Know What to Drop: Self-Attention Guided KV Cache Eviction ...
KV Cache Optimization via Tensor Product Attention - PyImageSearch ...
Introduction to KV Cache Optimization Using Grouped Query Attention ...
KV Cache Optimization via Multi-Head Latent Attention - PyImageSearch
KV Cache in Large Language Models: Design, Optimization, and Inference ...
Paper page - Task-KV: Task-aware KV Cache Optimization via Semantic ...
[QA] RocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV ...
MixAttention:跨层 KV Cache 共享 + 滑动窗口 Attention-AI.x-AIGC专属社区-51CTO.COM
[논문 리뷰] Efficient Memory Management for Large Language Model Serving ...
[论文阅读] Efficient Memory Management for Large Language Model Serving ...
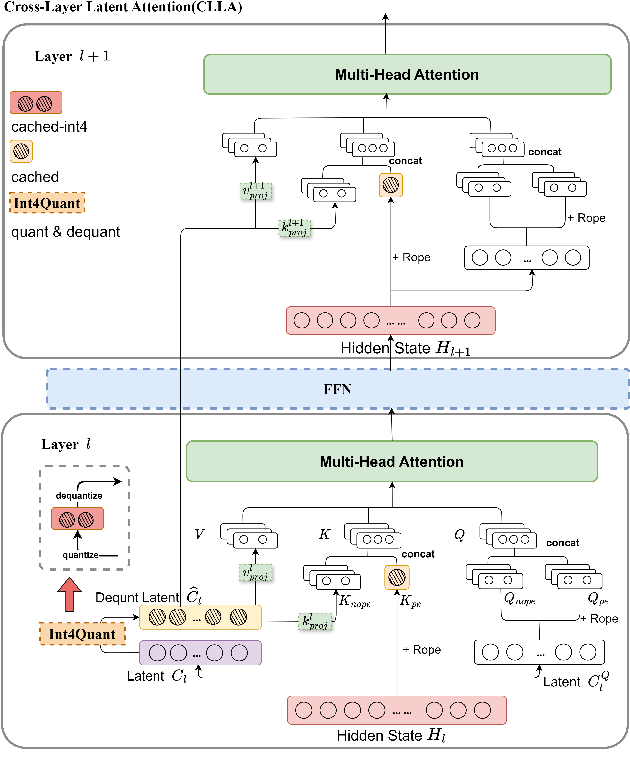
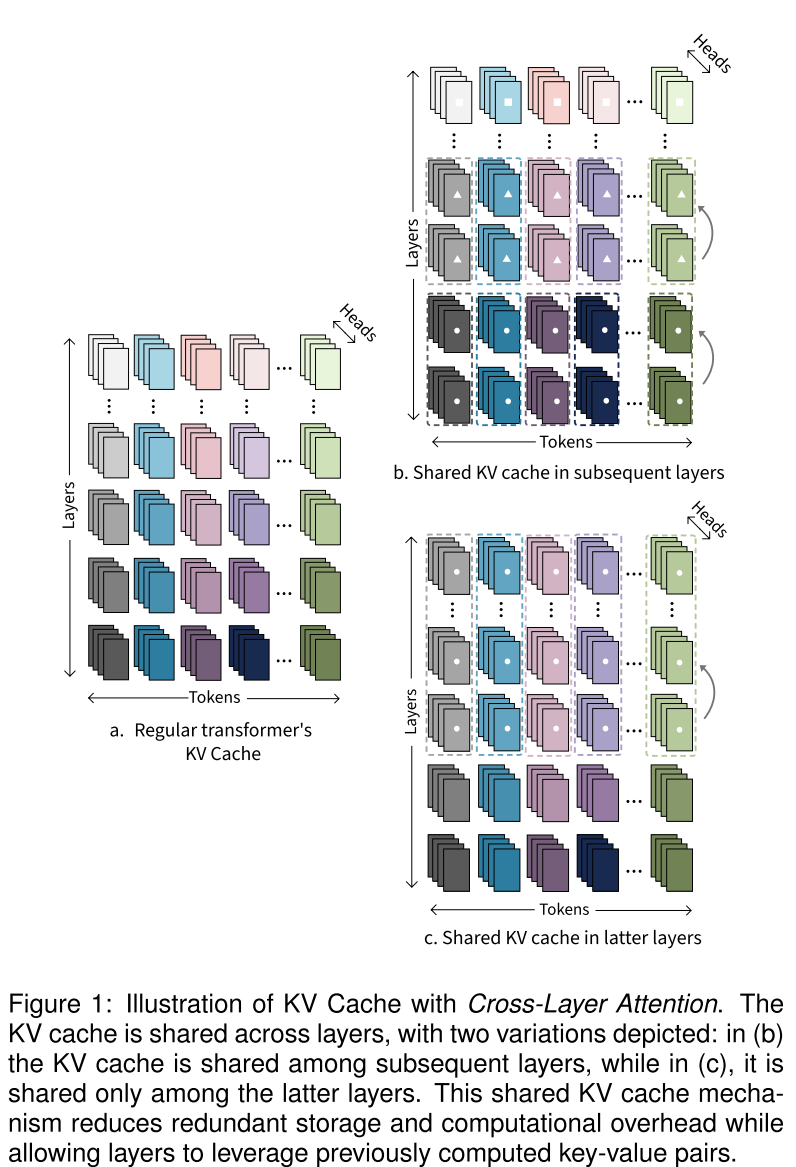
Memory-Efficient Inference: Smaller KV Cache with Cross-Layer Attention ...
Research | Systems for AI Lab
LLM inference optimization (1): KV Cache - MartinLwx's Blog
KV Cache Compression, But What Must We Give in Return? A Comprehensive ...
LLM(20):漫谈 KV Cache 优化方法,深度理解 StreamingLLM - 知乎
[2401.02669] Infinite-LLM: Efficient LLM Service for Long Context with ...
LLM 推理优化之 KV Cache - 知乎
KV Cache Optimization via Tensor Product Attention - PyImageSearch
Memory, Long-Context, and KV Caches | by aispotlightshow | Jan, 2026 ...
Efficient Streaming Language Models with Attention Sinks | Zhao Dongyu ...
Unlocking the Power of KV Cache: How to Speed Up LLM Inference and Cut ...
DuoAttention - 提高LLMs处理长上下文推理效率的AI框架 | AI工具集
KV cache稀疏之top k算法 - 知乎
(PDF) RocketKV: Accelerating Long-Context LLM Inference via Two-Stage ...
KV Cache的原理与实现_kuiperllama-CSDN博客
Paper page - ChunkAttention: Efficient Self-Attention with Prefix-Aware ...
Attention Mechanisms in Transformers: Comparing MHA, MQA, and GQA | Yue ...
人工智能 - LLM 推理优化探微 (3) :如何有效控制 KV 缓存的内存占用,优化推理速度? - IDP技术干货 ...
This AI Paper from China Introduces KV-Cache Optimization Techniques ...
20. Inference Acceleration (WIP) — LLM Foundations
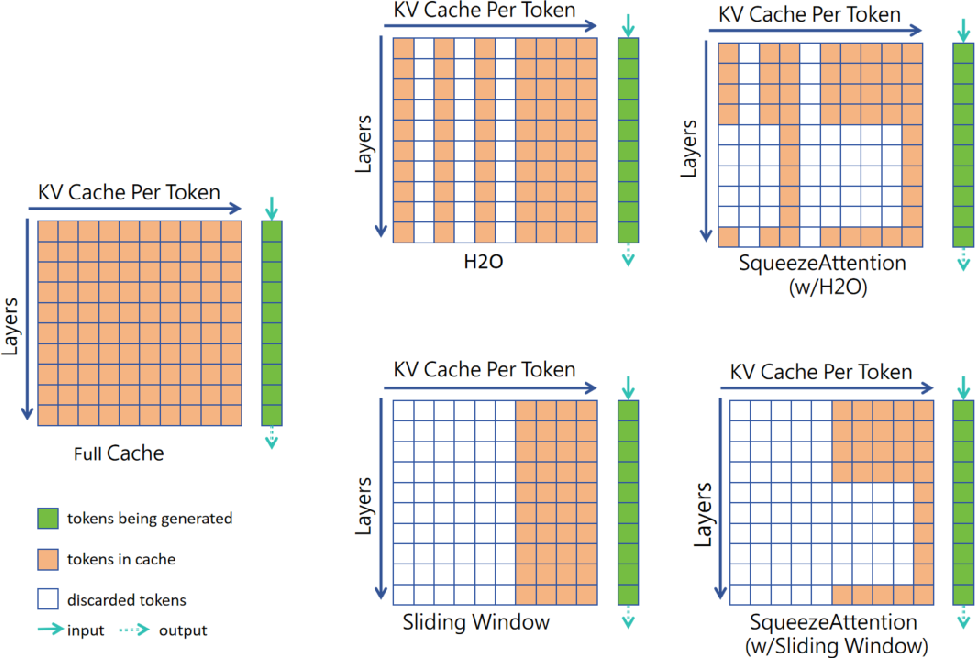
Figure 1 from SqueezeAttention: 2D Management of KV-Cache in LLM ...
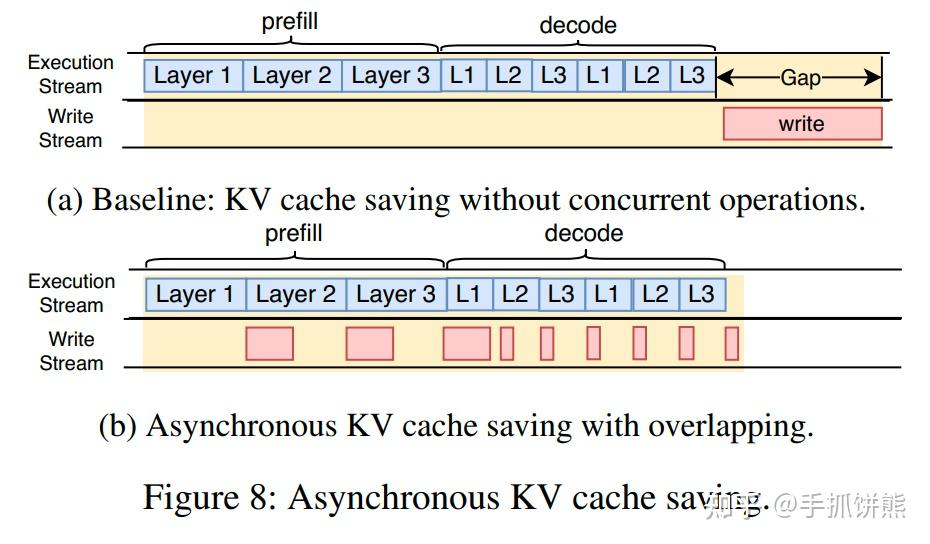
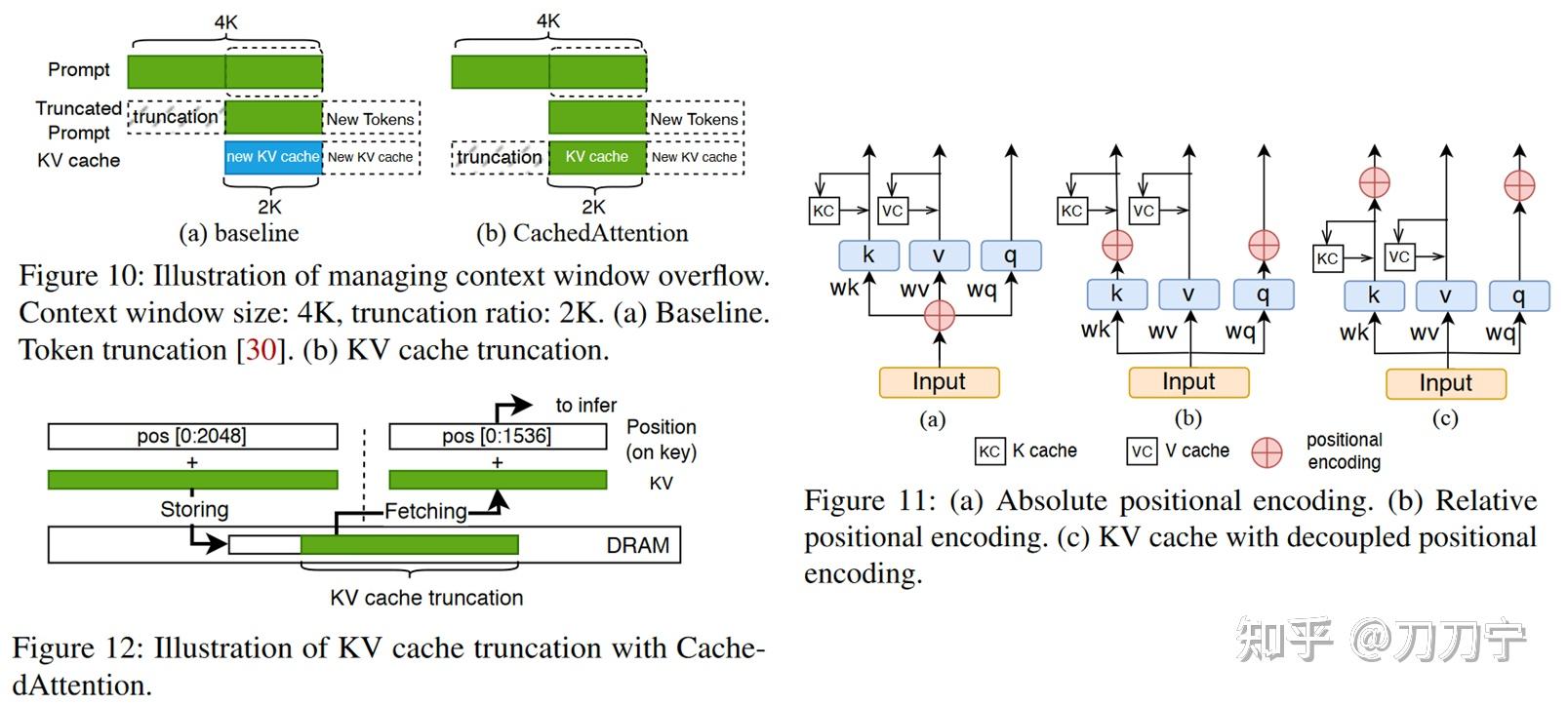
CachedAttention(原AttentionStore) - 知乎
LLM推理加速:kv cache优化方法汇总 - 知乎
KV缓存压缩下,大语言模型的核心能力能否保持?——全面评估与创新解决方案 - 知乎
大模型百倍推理加速之KV Cache稀疏篇 - 知乎
Awesome-Efficient-LLM/kv_cache_compression.md at main · horseee/Awesome ...
Blog - PyImageSearch
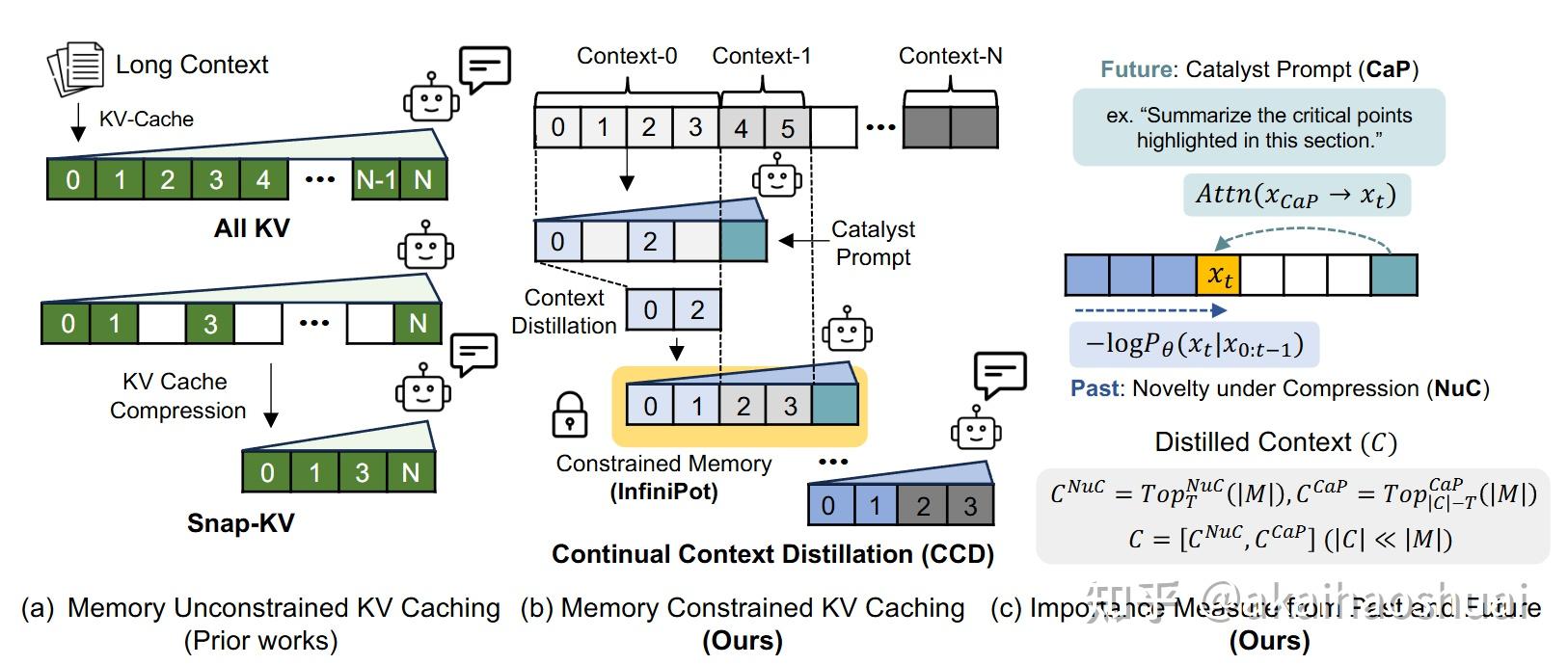
LongSight: Compute-Enabled Memory to Accelerate Large-Context LLMs via ...
[深度学习论文笔记]A Tri-attention Fusion Guided Multi-modal Segmentation ...
聊聊大模型推理内存管理之 CachedAttention/MLA - 知乎
【论文学习】理解LLM中的KV Cache和Paged Attention:深入探讨高效推理 - 知乎
Aman's AI Journal • Primers • Transformers
高效Attention引擎是怎样炼成的?陈天奇团队FlashInfer打响新年第一枪! - 智源社区
为解决显存与性能问题深度剖析Attention从KV缓存到稀疏化演进-开发者社区-阿里云
大模型推理优化-Paged Attention - 知乎
Mastering Long Contexts in LLMs with KVPress
文章收藏 2 万字总结:全面梳理大模型 Inference 相关技术 - 知乎
大模型百倍推理加速之KV cache篇 - 知乎
LLM推理优化技术综述:KVCache、PageAttention、FlashAttention、MQA、GQA - 知乎
深度学习常用的Attention操作(MHA/Casual Attention)以及内存优化管理(Flash Attention/Page ...
KV缓存:加速LLM推理 - 汇智网
LLM推理性能优化:KV Cache技术演进解析 - 开发技术 - 冷月清谈