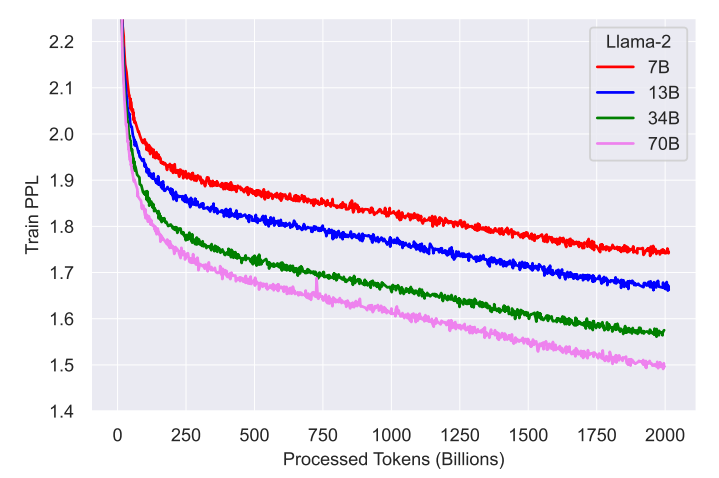
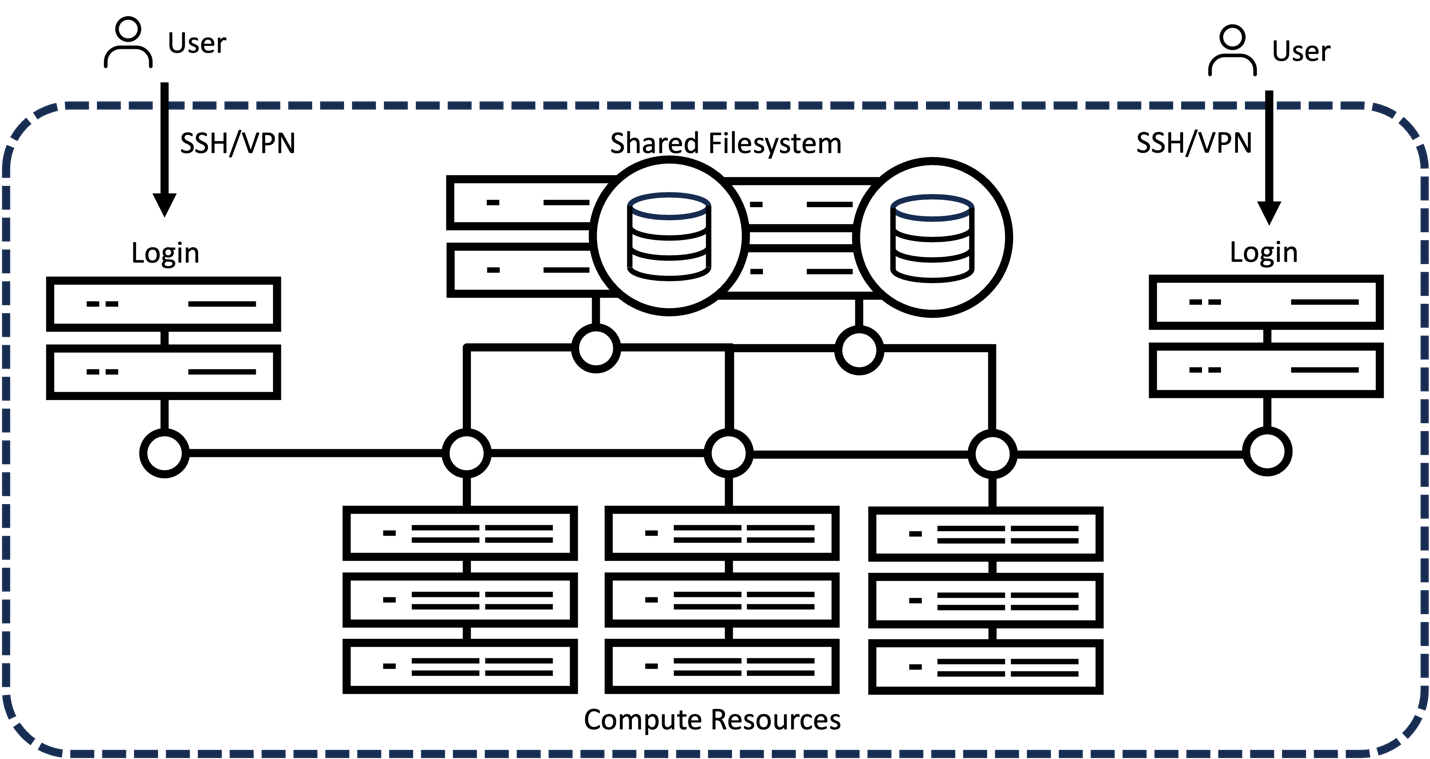
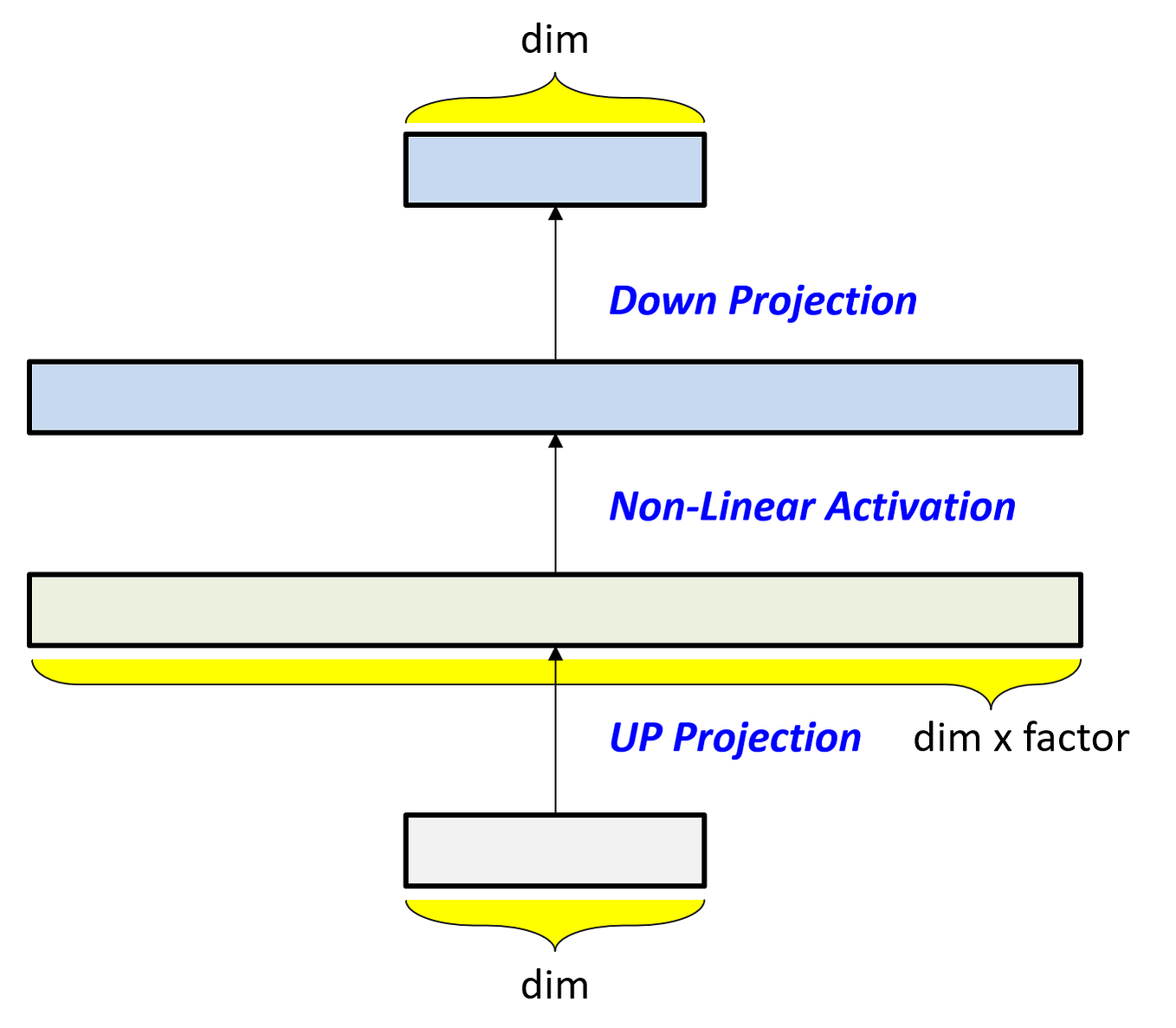
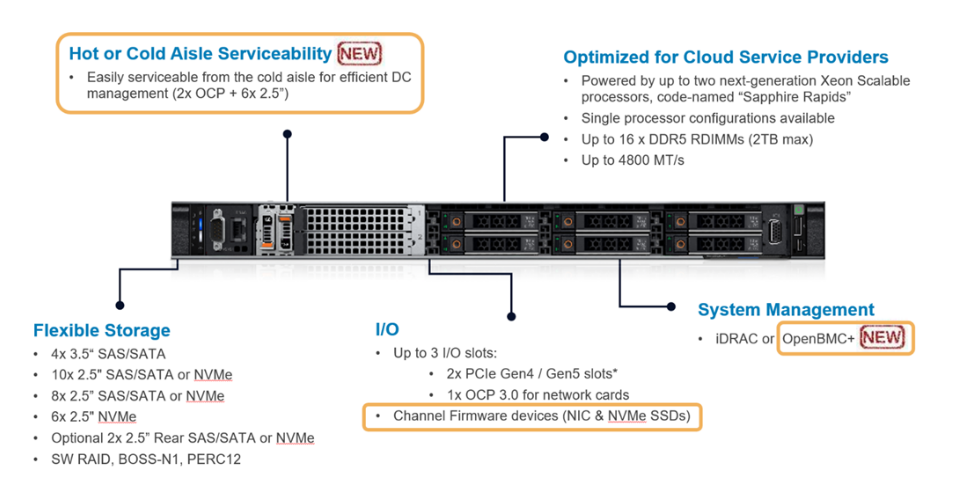
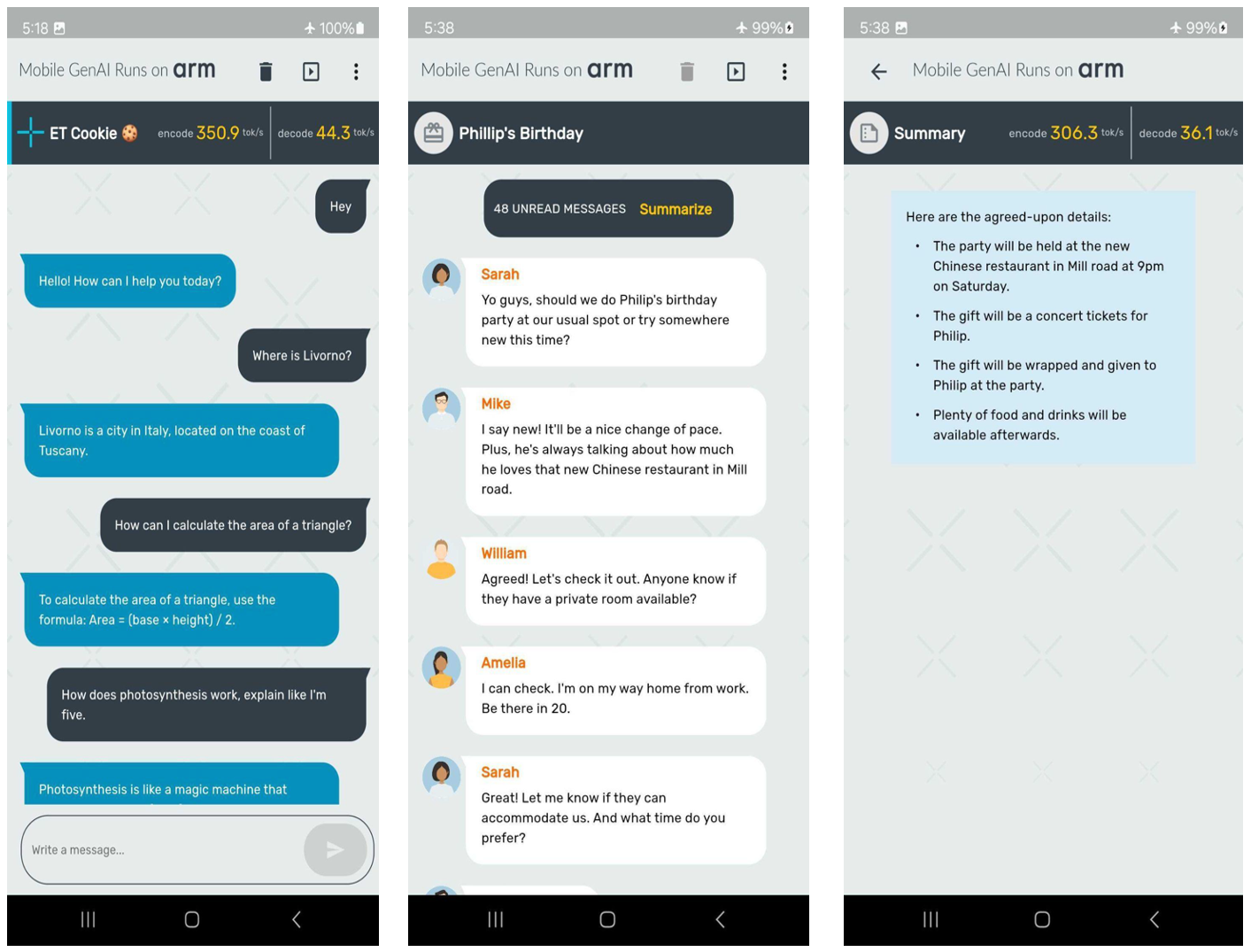
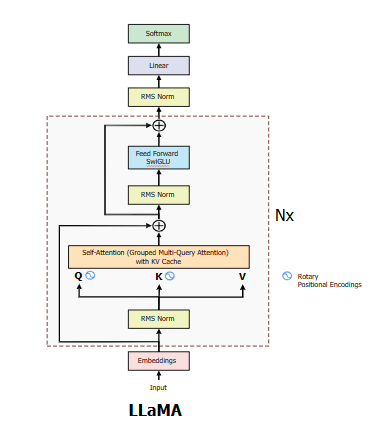
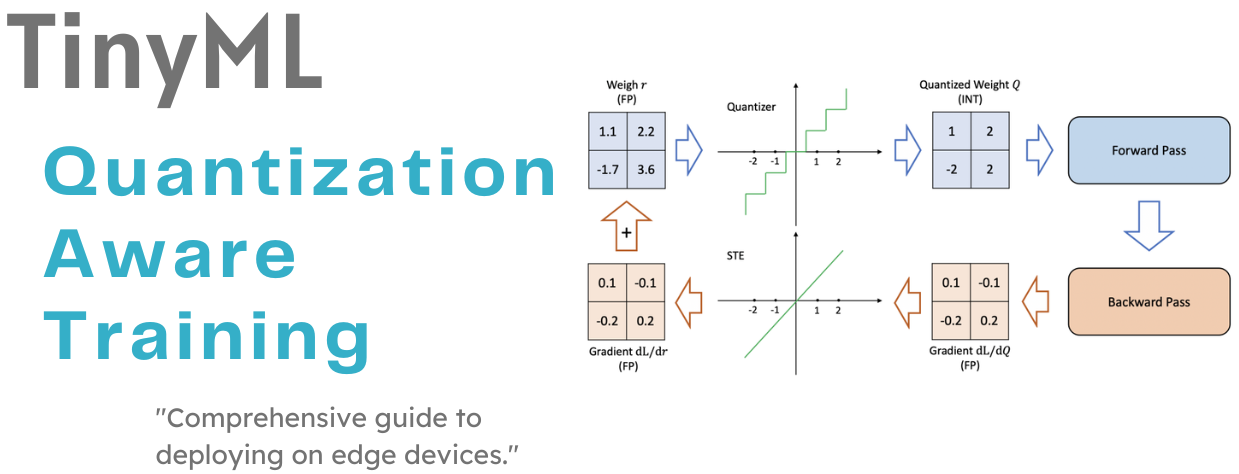
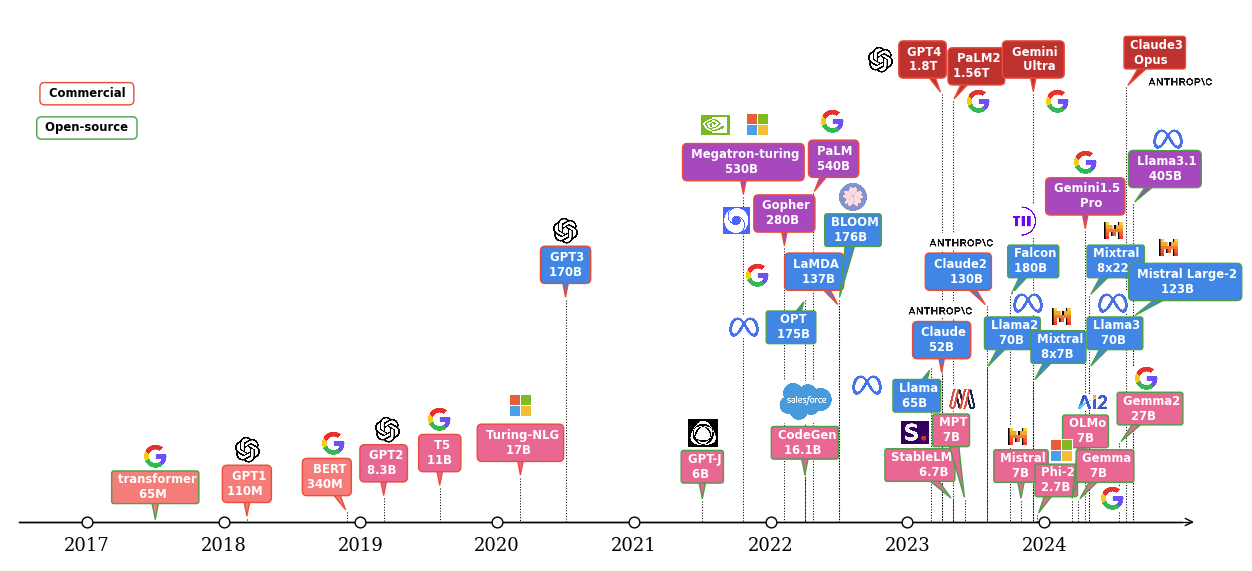
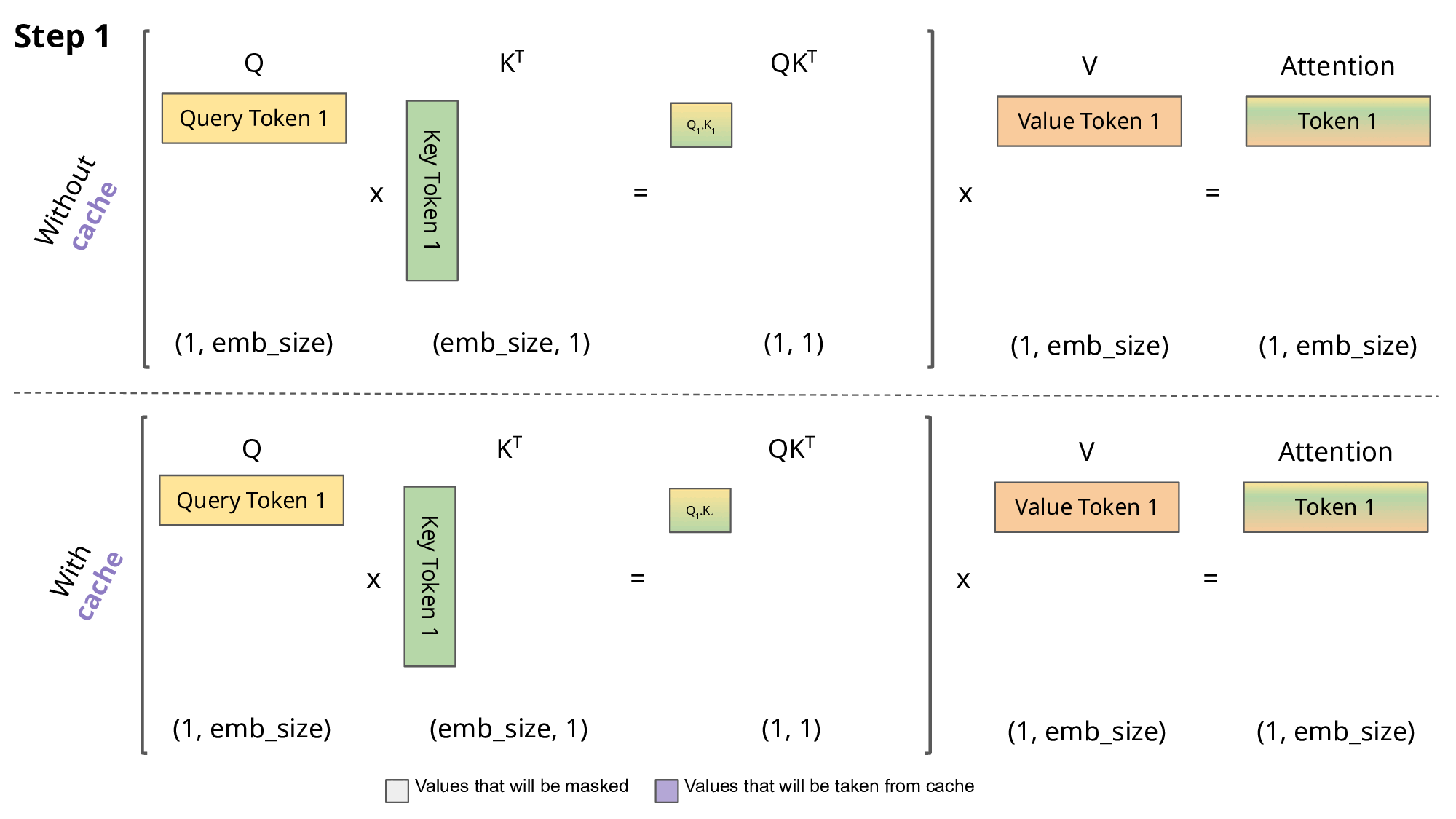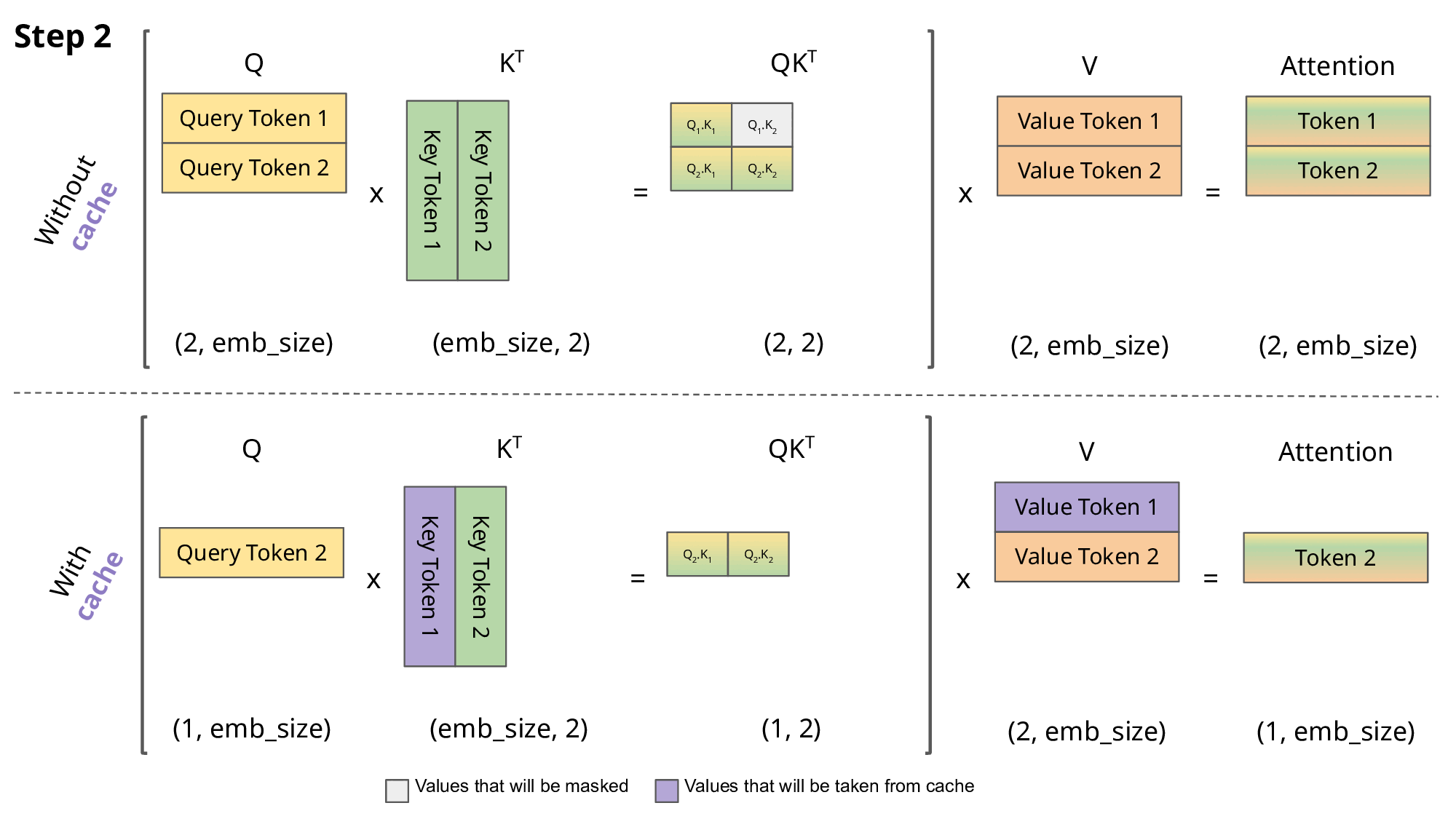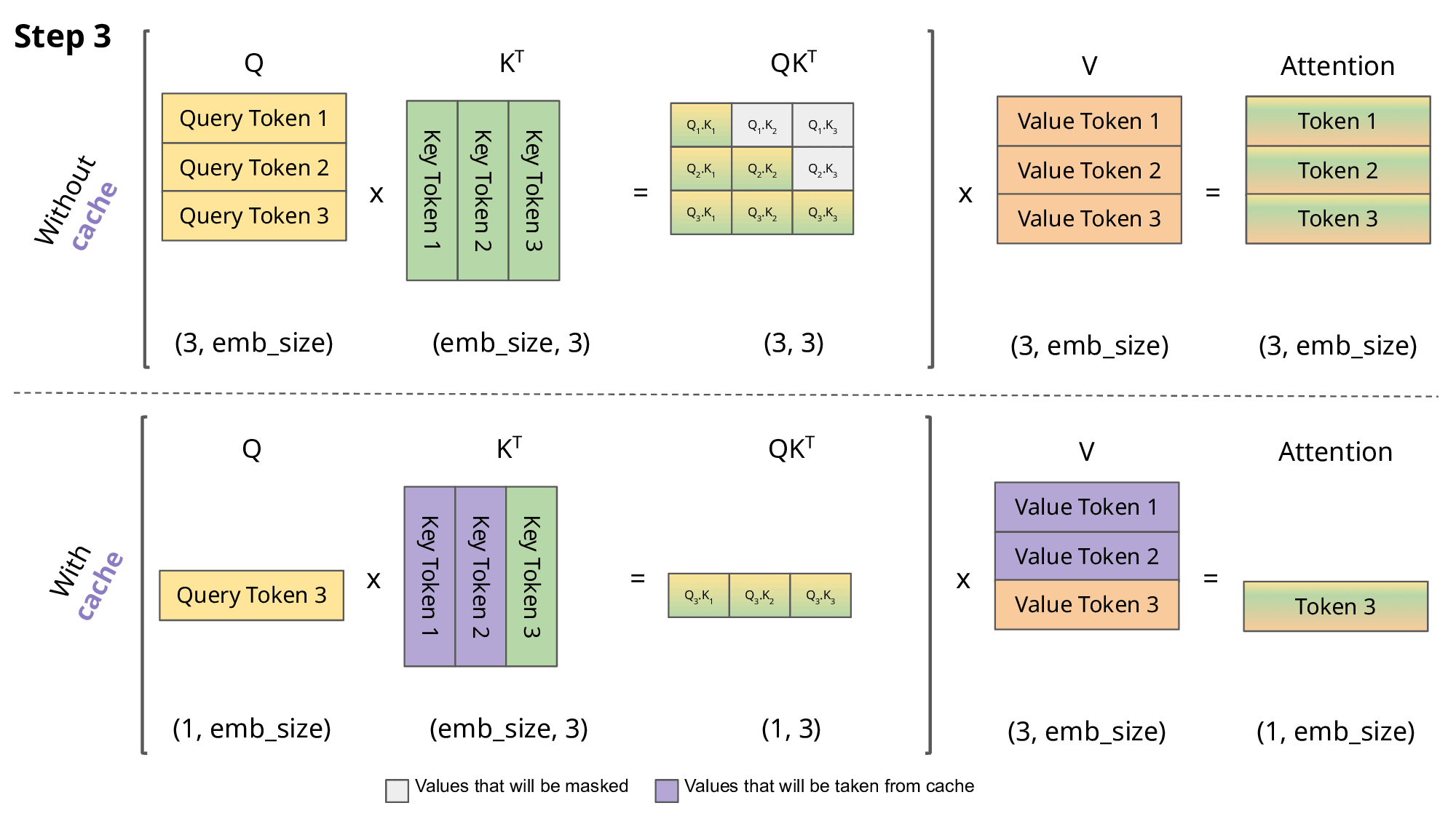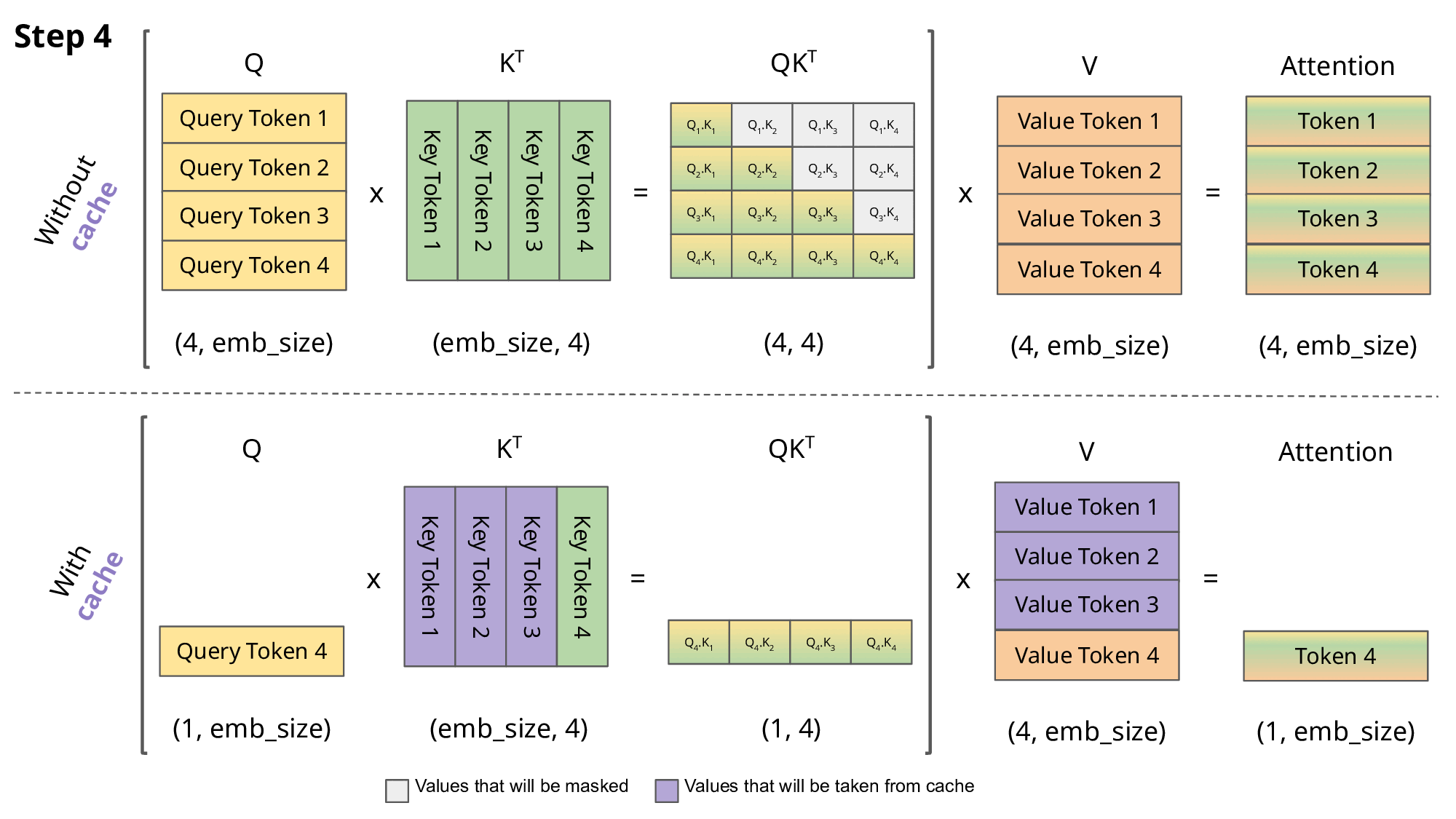
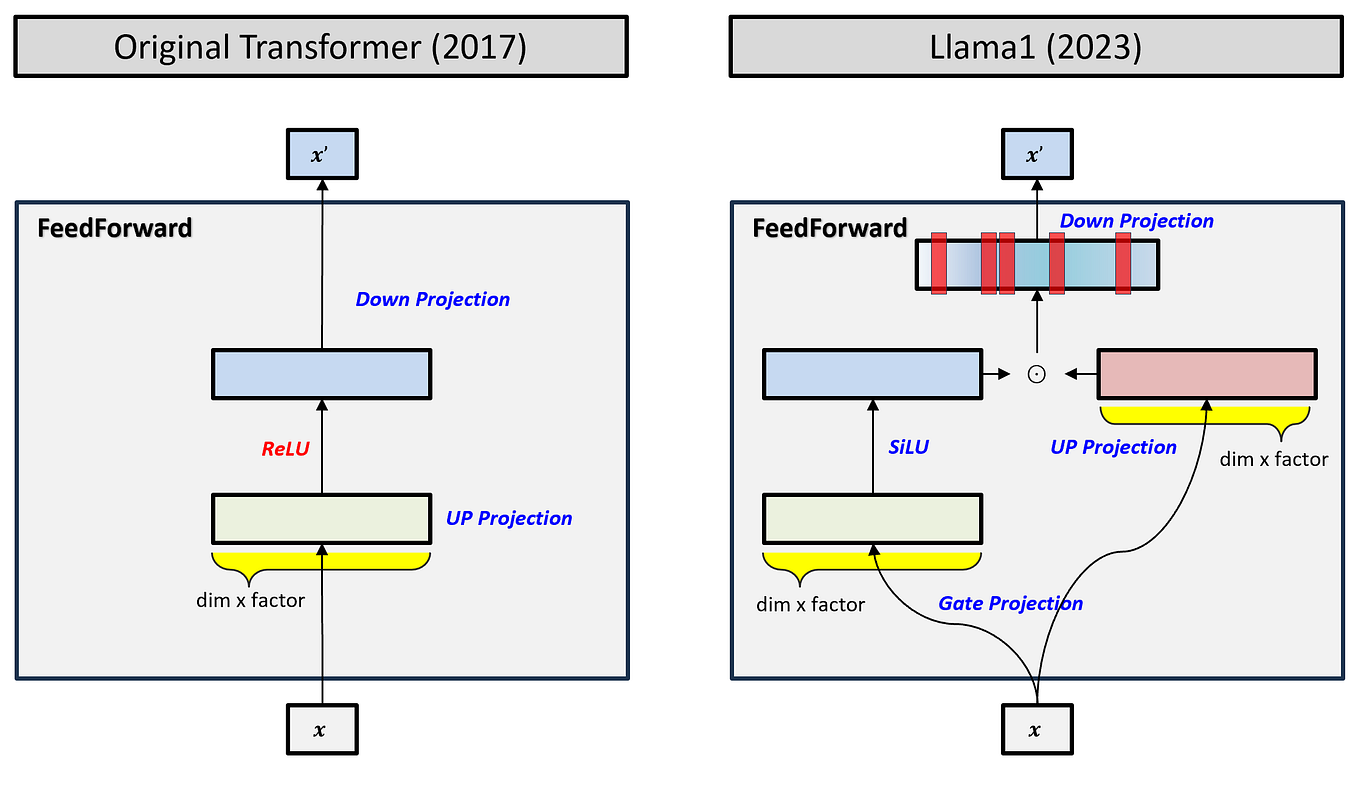
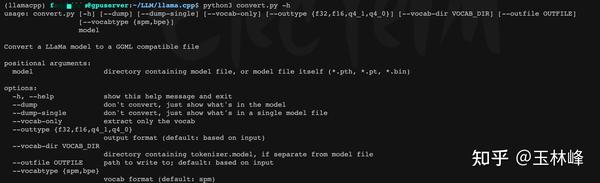
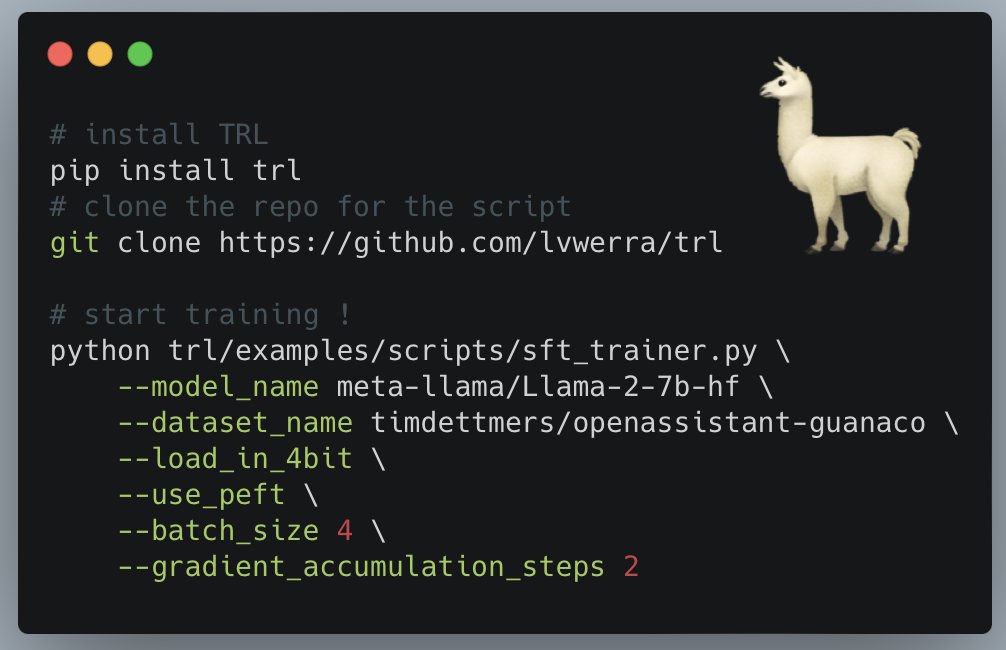
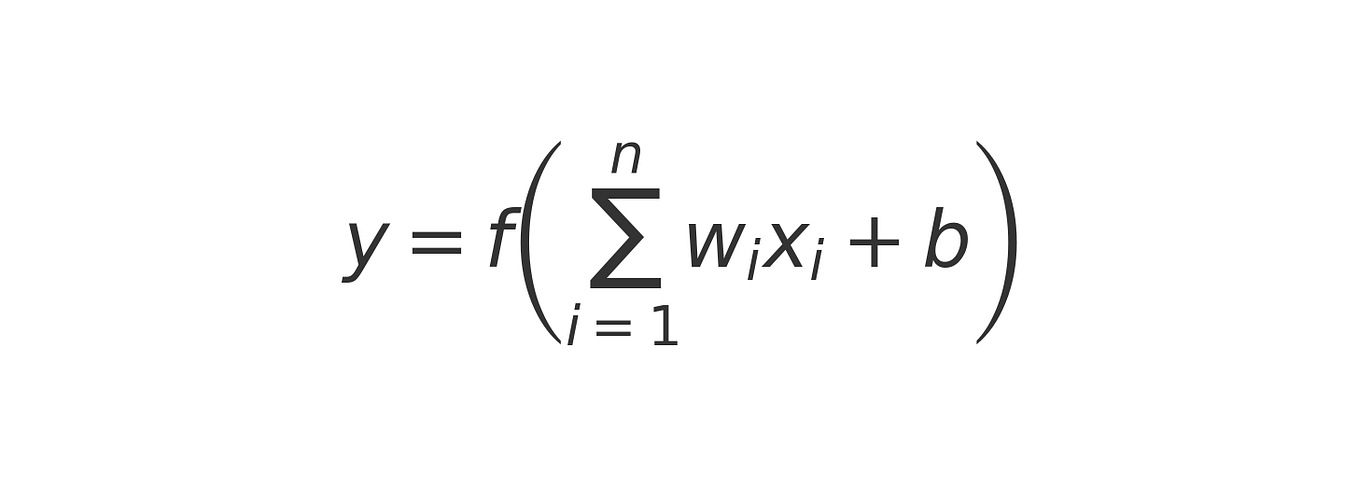Building and Quantizing Llama-2 from Scratch: Implementing a 7B ...
Free Video: Running Gemma 2B and Llama-2 7B with Model Quantization - A ...
Exploring and building the LLaMA 3 Architecture : A Deep Dive into ...
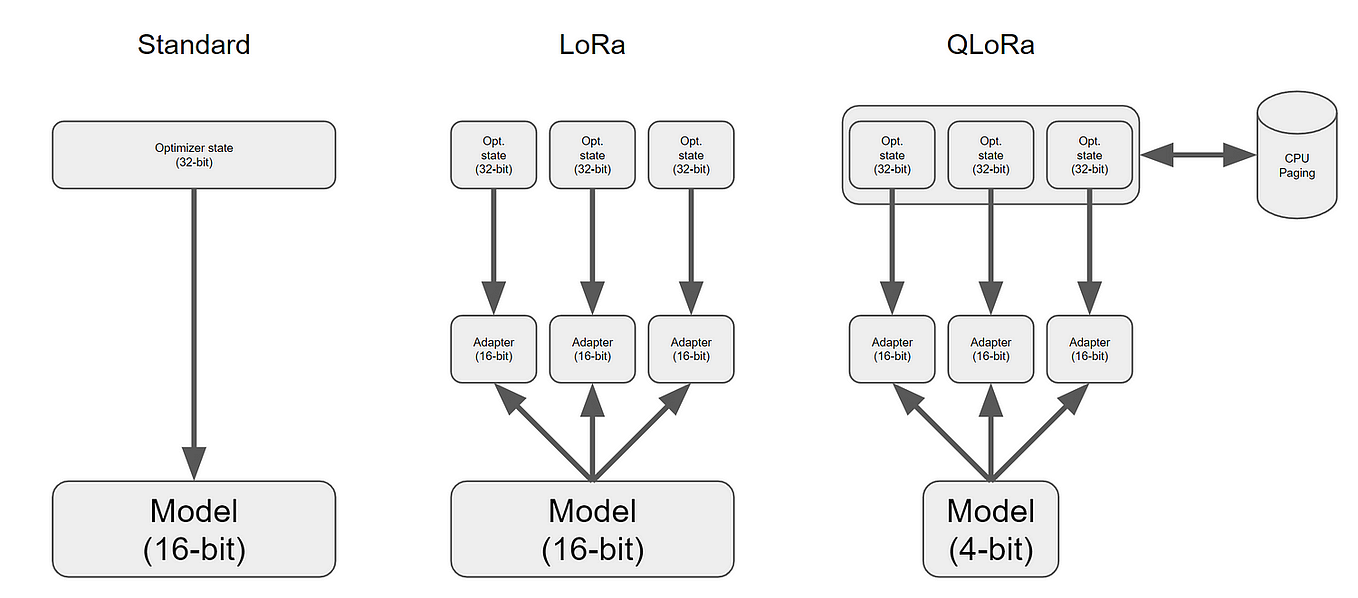
Building Efficient Fine-tuning with LoRA, QLoRA and Quantization from ...
Quantizing Large Language Models: A step by step example with Meta ...
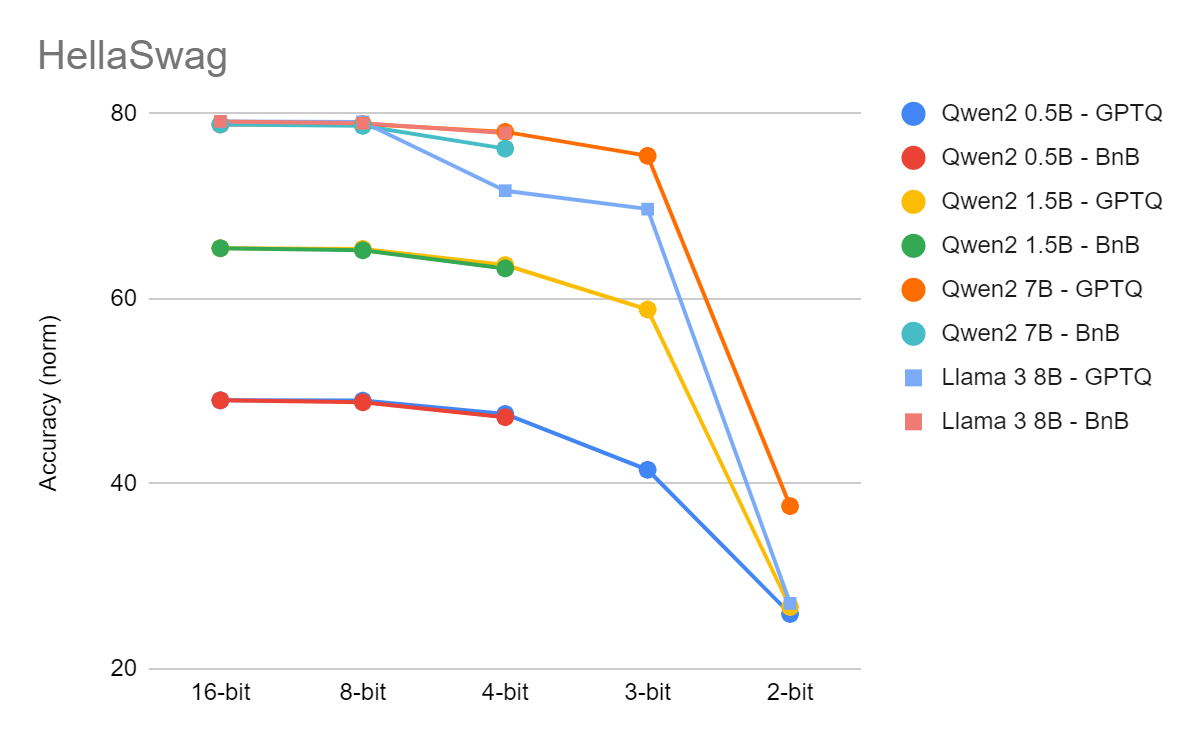
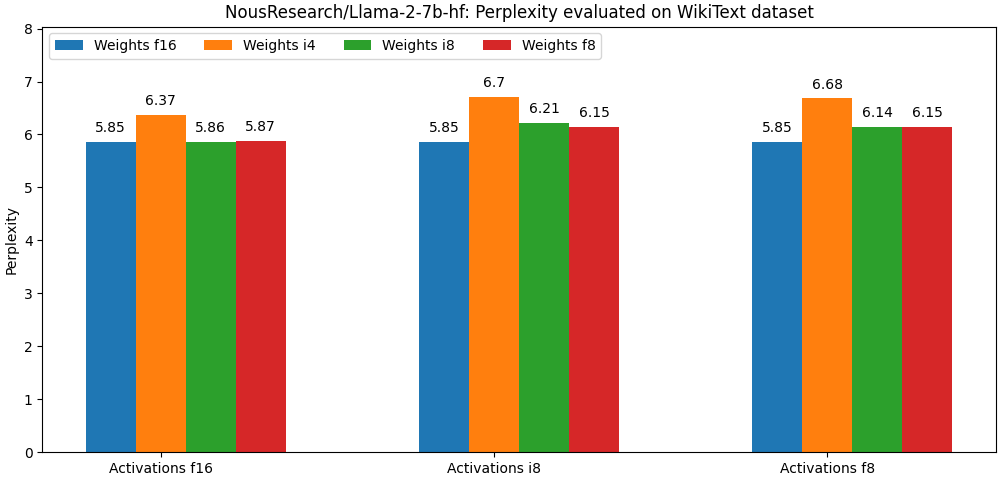
4-Bit VS 8-Bit Quantization Performance Comparison on Llama-2 and ...
Introducing quantized Llama models with increased speed and a reduced ...
Quantizing LLMs with llama.cpp. A practical guide to creating… | by ...
Fine-tune Llama-2 with a few lines of code! 🤯 Here, I leverage 4-bit ...
How to build a chatbot using open-source LLMs like Llama 2 and Falcon ...
Simple Tutorial to Quantize Models using llama.cpp from safetensors to ...
“Mastering Llama Math (Part-1): A Step-by-Step Guide to Counting ...
TinyLlama: Pre-training a Small Llama 2 from Scratch
Deploying Llama 7B Model with Advanced Quantization Techniques on Dell ...
Mastering LLama —Layer Normalization and RMSNorm | by Hugman Sangkeun ...
Free Video: LLM Quantization Tutorial: QLoRA, GPTQ, and LLama.cpp ...
Build Your Own Llama 3 Architecture from Scratch Using PyTorch | by ...
Building Llama 3 ChatBot Part 1: Quantization using AutoGPTQ | by ...
Learning Vector Quantization (LVQ): A Step-by-Step Guide with Code ...
TheBloke/Llama-2-70B-Chat-GPTQ · can u show the settings for quantizing ...
Quantizing Llama 3.2 with llama.cpp – A Practical Guide - DEV Community
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
Challenges in Quantizing llama.cpp Models on Windows · ggml-org llama ...
The Power of Llama 2: Leveraging Quantization and LangChain for ...
GitHub - aju22/LLaMA2: This repository contains an implementation of ...
Quantization of Llama 2 with GTPQ for Fast Inference on Your Computer ...
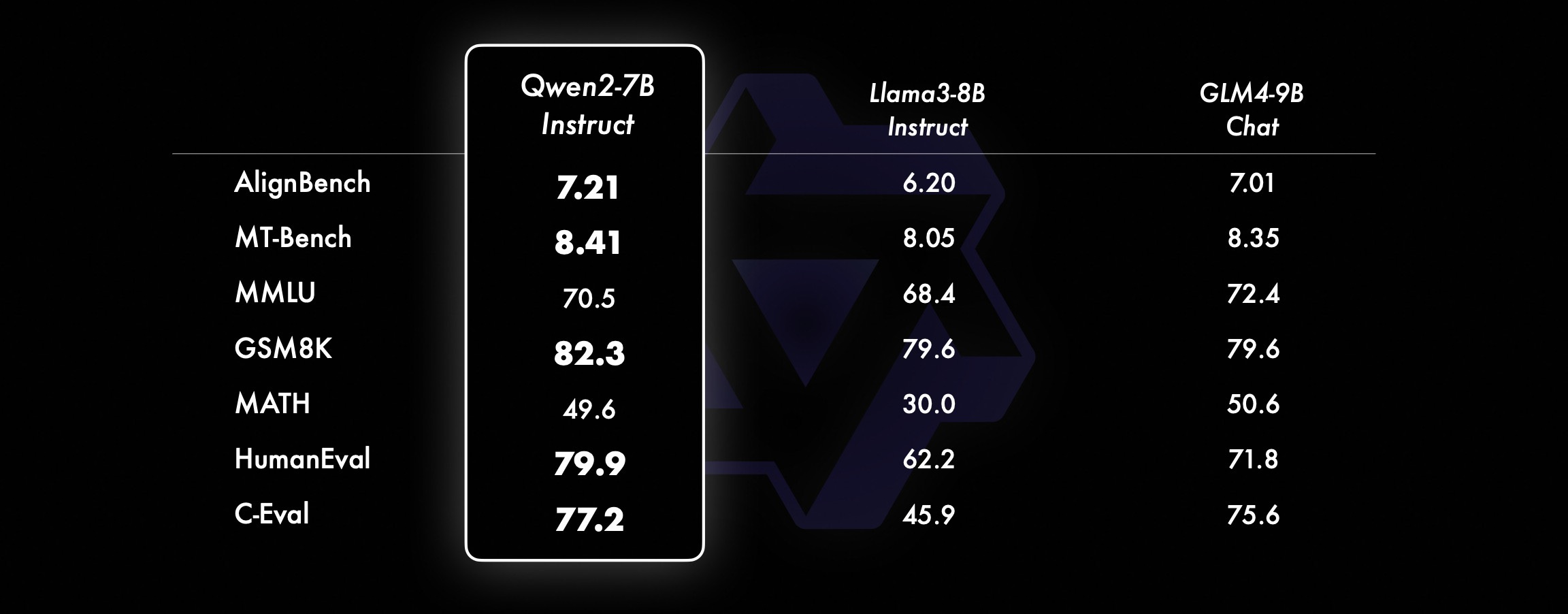
Qwen2 vs. Llama 3: QLoRA Learning Curves and Quantization Performance
1-bit and 2-bit Llama 3: Quantization with HQQ and Fine-tuning with HQQ+
Tutorial: Quantizing Llama 3+ Models for Efficient Deployment
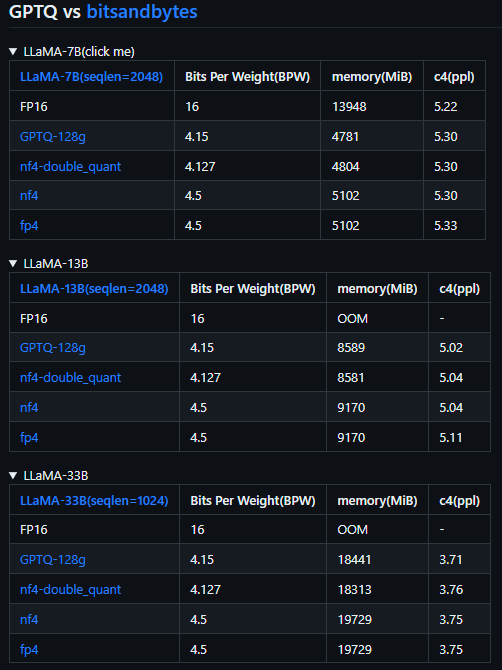
GPTQ or bitsandbytes: Which Quantization Method to Use for LLMs ...
LLM Quantization with llama.cpp on Free Google Colab | Llama 3.1 | GGUF ...
Quantize Llama models with GGML and llama.cpp | Towards Data Science
Quantizing Llama 70B for Production - Lattice Blog
LLAMA 2 LLAMA.cpp and Quantization on Ubuntu - YouTube
How to Use Llama.cpp for Quantizing Gemma-2-9B-It-SPPO-Iter3 fxis.ai
GitHub - tejus-vignesh/Fine-tune-Quantized-LLAMA2-7B-QLoRA-Code ...
Qwen3 From Scratch | Sebastian Raschka, PhD
DrishtiSharma/llama-2-chat-gptq-block-quantization-even-layers-attempt1 ...
Running LLM Models (LLaMA, Alpaca, LLaMA2, ChatGLM) on Raspberry Pi 4B ...
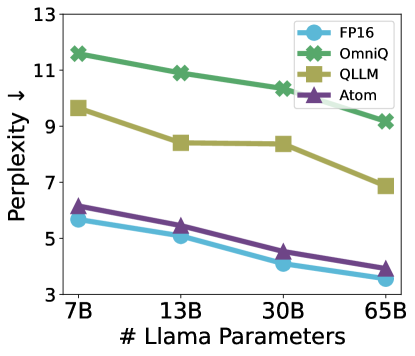
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language ...
Mistral 7B Model Architecture explanation | by Chamabouabd | Medium
Quantization Aware Training. Train the model taking quantization… | by ...
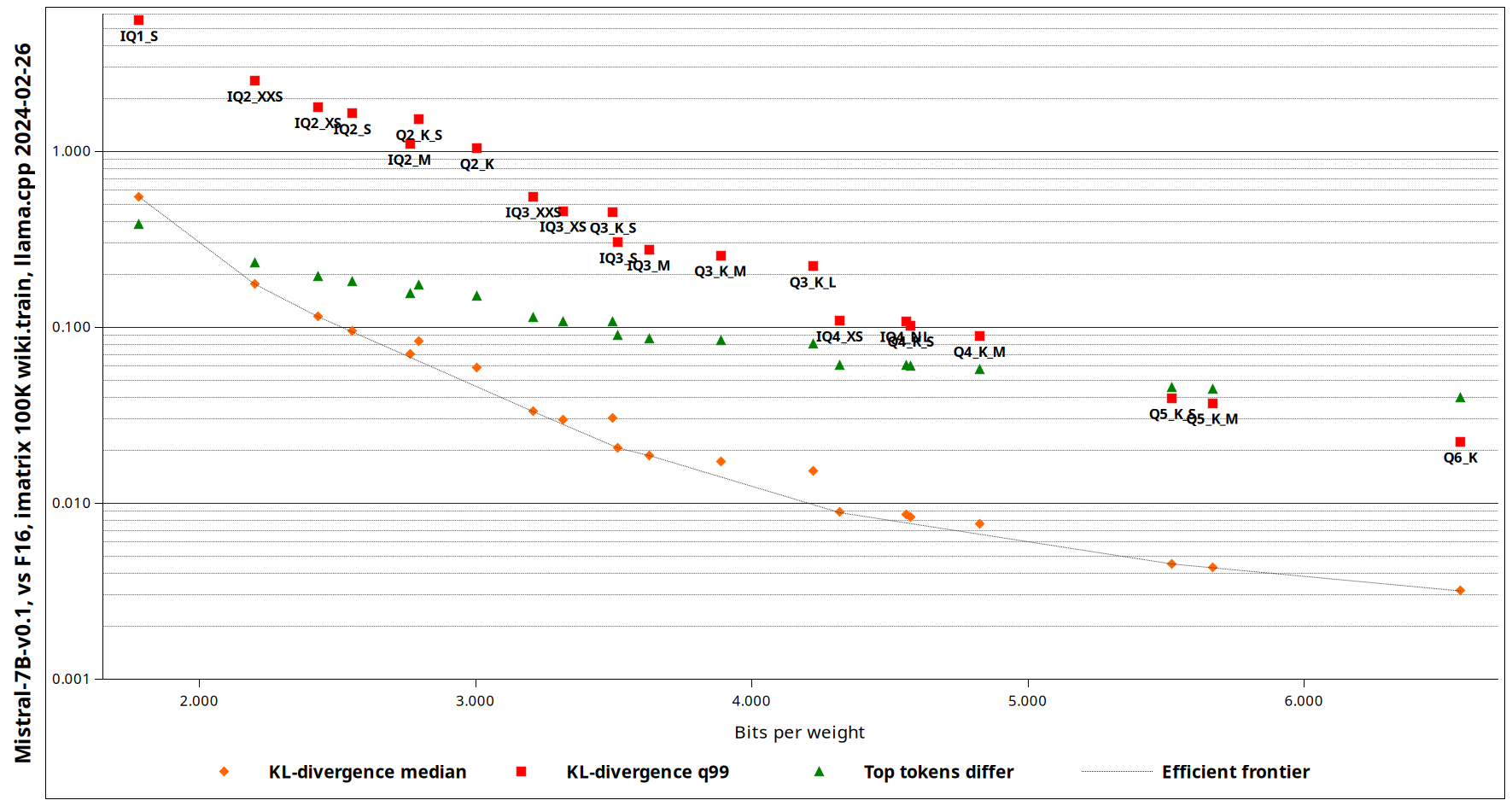
Step-by-Step Model Merging and GGUF imatrix Quantization
meta-llama/Llama-3.2-1B Quantized - a HF-Quantization Collection
Unleashing the Power of AI on Mobile: LLM Inference for Llama 3.2 ...
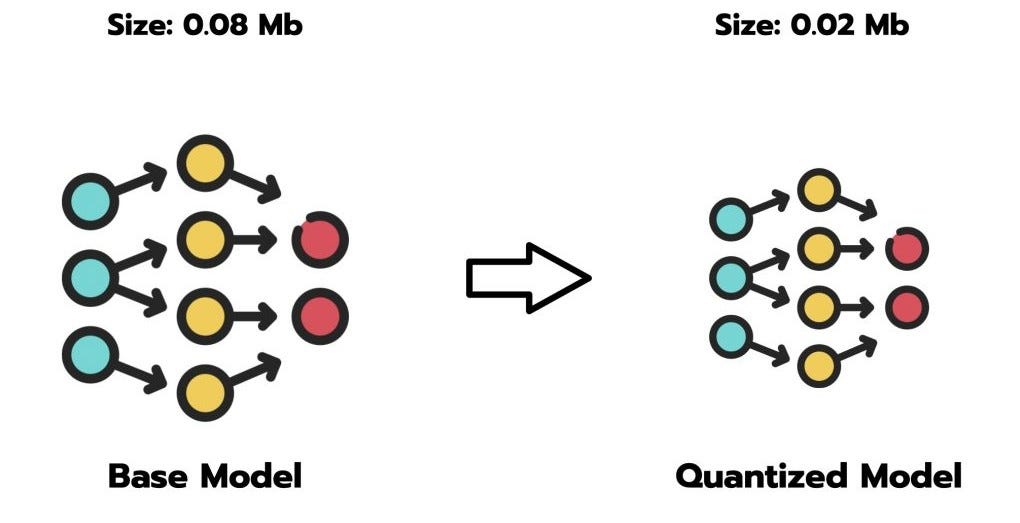
Understanding why quantization is beneficial in Neural Network ...
Llama-3 8B Model Stats. Llama-3 8B with 4-bit quantization only… | by ...
Deploying Llama 8B Model with Advanced Quantization Techniques on Dell ...
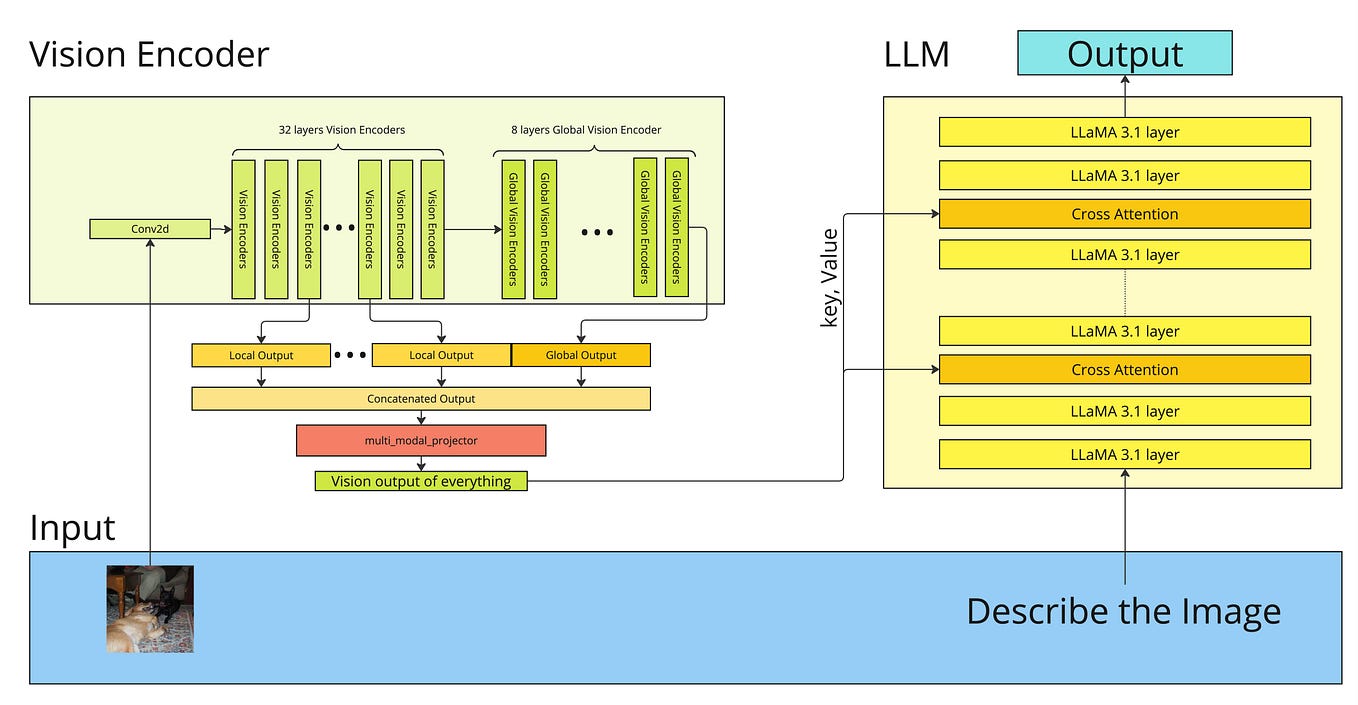
Llama 4 Technical Analysis: Decoding the Architecture Behind Meta’s ...
QuIP: 2-Bit Quantization of Large Language Models With Guarantees : r ...
Llama 2 7b-chat-hf 8-bit Quantization Fine Tuning With LoRA - YouTube
Exploring Residual Connections In Transformers | by Ryan Partridge | Medium
replicate/llama-7b | Run with an API on Replicate
[llm_python]beomi/llama-2-ko-7b 4bit quantization 양자화 모델 구동하기
llama.cpp 推理教程 - RWKV 中国
Quantization of Llama 2 with GTPQ for Fast Inference on Your Computer
2 to 6 bit quantization coming to llama.cpp : r/LocalLLaMA
【llm大语言模型】一文看懂llama2(原理,模型,训练) - 知乎
llama.cpp |在你笔记本上就能跑起来llama2-7B! - 知乎
Run LLaMA on small GPUs: LLM Quantization in Python - YouTube
Quantization of LLMs with llama.cpp | by Ingrid Stevens | Medium
Shaina Raza, PhD posted on LinkedIn
Ubuntu llama 2搭建及部署,同时附问题与解决方案_llama ubuntu-CSDN博客
在MBP上运行推理LLaMA-7B&13B模型 - Xu_Lin - 博客园
List: Llama | Curated by Jack Liu | Medium
Hugging News #0814: Llama 2 学习资源大汇总 🦙 - 智源社区
使用GGML和LangChain在CPU上运行量化的llama2 - 知乎
GGUF quantization of LLMs with llama cpp - YouTube
[2310.19102] 1 Introduction
Pytorch 基本介紹與教學. Pytorch 是 Facebook 於 2017… | by 李謦伊 | 謦伊的閱讀筆記 | Medium
Exploring Model Quantization for LLMs | by Snehal | Medium
Quanto